We are happy to announce that the Augmented Vision group presented 2 papers in the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) that took place from the 4th -8th January 2024 in Waikoloa, Hawaii.
The BERTHA project receives EU funding to develop a Driver Behavioral Model that will make autonomous vehicles safer and more human-like
The project, funded by the European Union with Grant Agreement nº 101076360, will receive 7.9 M€ under the umbrella of the Horizon Europe programme.
The BERTHA project will develop a scalable and probabilistic Driver Behavioral Model which will be key to achieving safer and more human-like connected autonomous vehicles, thus increasing their social acceptance. The solution will be available for academia and industry through an open-source data HUB and in the CARLA autonomous driving simulator.
The project’s consortium gathered on 22-24 November for the kick-off meeting, hosted by the coordinator Instituto de Biomecánica de Valencia at its facilities in Spain.
The Horizon Europe project BERTHA kicked off on November 22nd-24th in Valencia, Spain. The project has been granted €7,981,799.50 from the European Commission to develop a Driver Behavioral Model (DBM) that can be used in connected autonomous vehicles to make them safer and more human-like. The resulting DBM will be available on an open-source HUB to validate its feasibility, and it will also be implemented in CARLA, an open-source autonomous driving simulator.
The project celebrated its kick-off meeting on November 22nd to 24th, hosted by the coordinator Instituto de Biomecánica de Valencia (IBV) at its offices in Valencia, Spain. During the event, all partners met each other, shared their technical backgrounds and presented their expected contributions to the project.
The need for a Driver Behavioral Model in the CCAM industry
The industry of Connected, Cooperative, and Automated Mobility (CCAM) presents important opportunities for the European Union. However, its deployment requires new tools that enable the design and analysis of autonomous vehicle components, together with their digital validation, and a common language between Tier vendors and OEM manufacturers.
One of the shortcomings arises from the lack of a validated and scientifically based Driver Behavioral Model (DBM) to cover the aspects of human driving performance, which will allow to understand and test the interaction of connected autonomous vehicles (CAVs) with other cars in a safer and predictable way from a human perspective.
Therefore, a Driver Behavioral Model could guarantee digital validation of the components of autonomous vehicles and, if incorporated into the ECUs software, could generate a more human-like response of such vehicles, thus increasing their acceptance.
The contributions of BERTHA to the autonomous vehicles industry and research
To cover this need in the CCAM industry, the BERTHA project will develop a scalable and probabilistic Driver Behavioral Model (DBM), mostly based on Bayesian Belief Network, which will be key to achieving safer and more human-like autonomous vehicles.
The new DBM will be implemented on an open-source HUB, a repository that will allow industrial validation of its technological and practical feasibility, and become a unique approach for the model’s worldwide scalability.
The resulting DBM will be translated into CARLA, an open-source simulator for autonomous driving research developed by the Spanish partner Computer Vision System. The implementation of BERTHA’s DBM will use diverse demos which allow the building of new driving models in the simulator. This can be embedded in different immersive driving simulators as HAV from IBV.
BERTHA will also develop a methodology which, thanks to the HUB, will share the model with the scientific community to ease its growth. Moreover, its results will include a set of interrelated demonstrators to show the DBM approach as a reference to design human-like, easily predictable, and acceptable behaviour of automated driving functions in mixed traffic scenarios.
Teilnehmer des Kick-Off-Treffens des KIMBA Forschungsvorhabens stehen vor einem mobilen Prallbrecher von Projektpartner KLEEMANN. // Participants of the kick-off meeting of the KIMBA research project standing in front of a mobile impact crusher from project partner KLEEMANN
[Deutsche Version]
Im Rahmen der Digital GreenTech Konferenz 2023 in Karlsruhe wurden kürzlich 14 neue Forschungsprojekte aus den Bereichen Wasserwirtschaft, nachhaltiges Landmanagement, Ressourceneffizienz und Kreislaufwirtschaft vorgestellt, darunter auch Kimba. Hierbei arbeiten wir gemeinsam mit unseren Projektpartnern an einer KI-basierten Prozesssteuerung und automatisiertem Qualitätsmanagement für das Recycling von Bau- und Abbruchabfällen in Echtzeit. Das spart Kosten, Zeit sowie Ressourcen und schont die Umwelt. So unterstützen wir die Baubranche auf ihrem Weg in die Zukunft.
At the Digital GreenTech Conference 2023 in Karlsruhe, 14 new research projects in the fields of water management, sustainable land management, resource efficiency and circular economy were recently presented, including Kimba. Here, we are working with our project partners on AI-based process control and automated quality management for recycling construction and demolition waste in real time. This saves costs, time and resources and protects the environment. This is how we support the construction industry on its way into the future.
Alt-Text: Teilnehmer des Kick-Off-Treffens des ReVise-UP Forschungsvorhabens stehen vor dem Bergbaugebäude der RWTH Aachen University. // Participants of the kick-off meeting of the ReVise-UP research project stand in front of the mining building of RWTH Aachen University.
Deutsche Version
Forschungsvorhaben „ReVise-UP“ zur Verbesserung der Prozesseffizienz des werkstofflichen Kunststoffrecyclings mittels Sensortechnik gestartet
Im September 2023 startete das vom BMBF geförderte Forschungsvorhaben ReVise-UP („Verbesserung der Prozesseffizienz des werkstofflichen Recyclings von Post-Consumer Kunststoff-Verpackungsabfällen durch intelligentes Stoffstrommanagement – Umsetzungsphase“). In der vierjährigen Umsetzungsphase soll die Transparenz und Effizienz des werkstofflichen Kunststoffrecyclings durch Entwicklung und Demonstration sensorbasierter Stoffstromcharakterisierungsmethoden im großtechnischen Maßstab gesteigert werden.
Auf Basis der durch Sensordaten erzeugten Datentransparenz soll das bisherige Kunststoffrecycling durch drei Effekte verbessert werden: Erstens sollen durch die Datentransparenz positive Anreize für verbesserte Sammel- und Produktqualitäten und damit gesteigerte Rezyklatmengen und -qualitäten geschaffen werden. Zweitens sollen sensorbasiert erfasste Stoffstromcharakteristika dazu genutzt werden, Sortier-, Aufbereitungs- und Kunststoffverarbeitungsprozesse auf schwankende Stoffstromeigenschaften adaptieren zu können. Drittens soll die verbesserte Datenlage eine ganzheitliche ökologische und ökonomische Bewertung der Wertschöpfungskette ermöglichen.
Research project “ReVise-UP” started to improve the process efficiency of mechanical plastics recycling using sensor technology
In September 2023, the BMBF-funded research project ReVise-UP (“Improving the process efficiency of mechanical recycling of post-consumer plastic packaging waste through intelligent material flow management – implementation phase”) started. In the four-year implementation phase, the transparency and efficiency of mechanical plastics recycling is to be increased by developing and demonstrating sensor-based material flow characterization methods on an industrial scale.
Based on the data transparency generated by sensor data, the current plastics recycling shall be improved by three effects: First, data transparency is intended to create positive incentives for improved collection and product qualities and thus increased recyclate quantities and qualities. Second, sensor-based material flow characteristics are to be used to adapt sorting, treatment and plastics processing processes to fluctuating material flow properties. Third, the improved data situation should enable a holistic ecological and economic evaluation of the value chain.
DFKI Augmented Vision researchers Praveen Nathan, Sandeep Inuganti, Yongzhi Su and Jason Rambach received their 1st place award in the prestigious BOP Object Pose Estimation Challenge 2023 in the categories Overall Best RGB Method,Overall Best Segmentation Method and The Best BlenderProc-Trained Segmentation Method.
The BOP benchmark and challenge addresses the problem of 6-degree-of-freedom object pose estimation, which is of great importance for many applications such as robot grasping or augmented reality. This year, the BOP challenge was held within the “8th International Workshop on Recovering 6D Object Pose (R6D)” http://cmp.felk.cvut.cz/sixd/workshop_2023/ at the International Conference on Computer Vision (ICCV) in Paris, France https://iccv2023.thecvf.com/ .
The awards were received by Yongzhi Su and Dr. Jason Rambach on behalf of the DFKI Team and a short presentation of the method followed. The winning method was based on the CVPR 2022 paper “ZebraPose”
The winning approach was developed by a team led by DFKI AV, with contributing researchers from Zhejiang University.
List of contributing researchers:
DFKI Augmented Vision: Praveen Nathan, Sandeep Inuganti, Yongzhi Su, Didier Stricker, Jason Rambach
On the 5th and 6th of September 2023, the new EU project dAIEdge “A network of excellence for distributed, trustworthy, efficient and scalable AI at the Edge“ officially took off.
The kick-off meeting held at DFKI in Kaiserslautern was an excellent occasion to meet with the 36 partners from 15 European countries and launch the activities of the network!
The main goal of dAIEDGE is to support and ensure the rapid development and market adoption of distributed edge AI technologies, such as hardware, software, frameworks, and tools.
The applications of dAIEDGE will be used in a wide range of domains, such as the Internet of Things (IoT), intelligent transportation systems, satellite imagery and robotics.
The network has a project volume of €14.4 million, of which €10.7 million is funded by the European Union. Looking forward to a fruitful collaboration and a successful project!
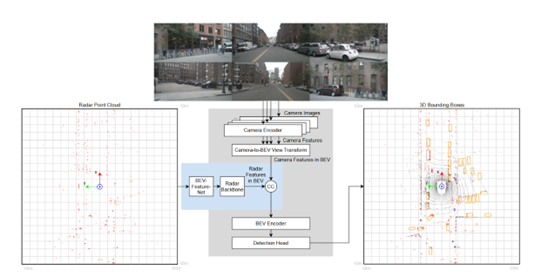
DFKI Augmented Vision is collaborating with Stellantis on the topic of Radar-Camera Fusion for Automotive Object Detection using Deep Learning. Recently, two new publications were accepted to the GCPR 2023 and EUSIPCO 2023 conferences.
The 2 new publications are:
1. Cross-Dataset Experimental Study of Radar-Camera Fusion in Bird’s-Eye View, Proceedings of the 31st. European Signal Processing Conference (EUSIPCO-2023), September 4-8, Helsinki, Finland, IEEE, 2023.
This paper investigates the influence of the training dataset and transfer learning on camera-radar fusion approaches, showing that while the camera branch needs large and diverse training data, the radar branch benefits more from a high-performance radar.
2. RC-BEVFusion: A Plug-In Module for Radar-Camera Bird’s Eye View Feature Fusion, Proceedings of. Annual Symposium of the German Association for Pattern Recognition (DAGM-2023), September 19-22, Heidelberg, BW, Germany, DAGM, 9/2023.
This paper introduces a new Bird’s Eye view fusion network architecture for camera-radar fusion for 3D object detection that performs favorably on the NuScenes dataset benchmark.
We are happy to announce that the Augmented Vision group will present 4 papers in the upcoming ICCV 2023 Conference, 2-6 October, Paris, France. The IEEE/CVF International Conference in Computer Vision (ICCV) is the premier international computer vision event. Homepage: https://iccv2023.thecvf.com/
The 4 accepted papers are:
U-RED: Unsupervised 3D Shape Retrieval and Deformation for Partial Point Clouds Yan Di, Chenyangguang Zhang, Ruida Zhang, Fabian Manhardt, Yongzhi Su, Jason Raphael Rambach, Didier Stricker, Xiangyang Ji, Federico Tombari
Introducing Language Guidance in Prompt-based Continual Learning Muhammad Gulzain Ali Khan, Muhammad Ferjad Naeem; Luc Van Gool; Federico Tombari; Didier Stricker, Muhammad Zeshan Afzal
DELO: Deep Evidential LiDAR Odometry using Partial Optimal Transport Sk Aziz Ali, Djamila Aouada, Gerd Reis, Didier Stricker
The first AI-Observer Summer School was held at the Eratosthenes Center of Excellence in Limassol, Cyprus, from July 10-14. Training sessions were given by Prof. Fabio Del Frate, Giorgia Guerrisi and Lorenzo Giuliano Papale (Tor Vergata University of Rome), and Dr. Gerd Reis (German Research Center for Artificial Intelligence). During the five-day hybrid event, more than 50 participants learned about the application of artificial intelligence in Earth observation, with special focus on disaster risk management. Topics included deforestation, flood detection, and natural hazard management using Sentinel-1 Synthetic Aperture RADAR (SAR), and Sentinel-2 Multi-Spectral Imaging (MSI) data.
We are glad to announce that our colleague Michael Lorenz won a best Paper award for his work On Motions artifacts arising when integrating inertial sensors into loose clothing such as a working jacket.
Abstract
Inertial human motion capture (IHMC) has become a robust tool to estimate human kinematics in the wild such as industrial facilities.
In contrast to optical motion capture, where occlusions might take place, the kinematics of a worker can be continuously provided.
This is for instance a prerequisite for an ergonomic assessments of the workers.
State-of-the-art IHMC solutions require inertial sensors to be tightly attached to body segments.
This requires an additional setup time and lowers the practicability and ease of use when it comes to an industrial application.
In contrast, sensors integrated into loose clothing such as a working jacket, may yield corrupted kinematics estimates due to the additional motion of loose clothing.
In this work we present a study of orientations deviations obtained from kinematics estimates using tightly attached inertial sensors and into a working jacket integrated ones.
We performed a quantitative analysis using data from the two hardware setups worn by 19 subjects performing different industry related tasks and measures of their body shapes.
Using this data we approximated probability distributions of the deviation angles for each person and body segment.
Applying different statistical measures we could gain insights to questions like, how severe orientation deviations are, if there is an influence of body shapes on the distribution and how probability distributions of the deviation angles can indicate physical motion limitations of a sensor attached to a segment.
On the 18.6, the team presented their solution and results as part of the workshop program. Scan-to-BIM solutions are of great importance for the construction community as they automate the generation of as-built models of buildings from 3D scans, and can be used for quality monitoring, robotic task planning and XR visualization, among other applications.
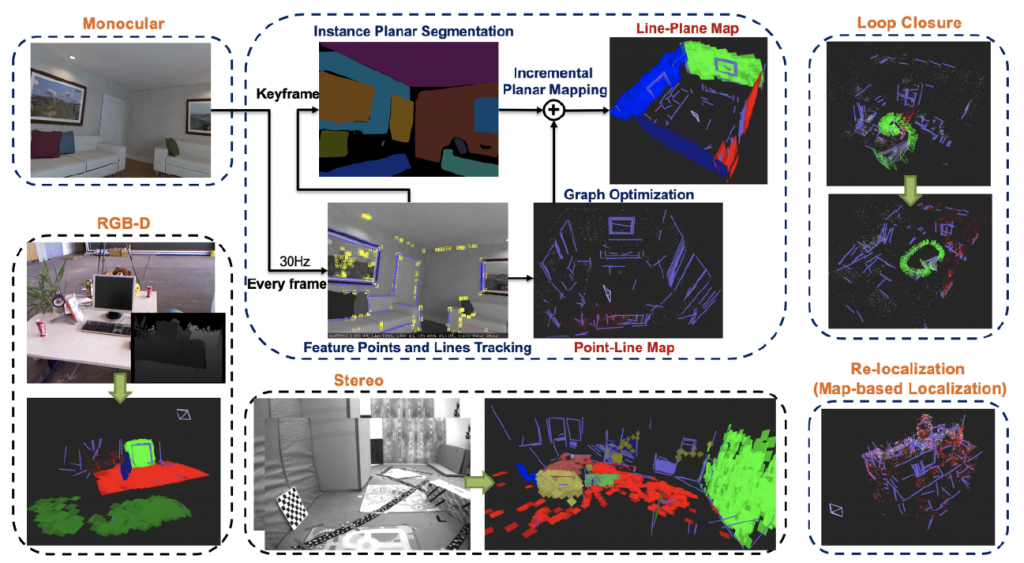
has been accepted at the IEEE International Conference on Robotics and Automation (ICRA) 2023.
In this paper, we present a visual SLAM system that uses both points and lines for robust camera localization, and simultaneously performs a piece-wise planar reconstruction (PPR) of the environment to provide a structural map in real-time. Our proposed SLAM tightly incorporates the semantic and geometric features to boost both frontend pose tracking and backend map optimization.
The ICRA conference takes place this year in London, from May 29th to June 2nd.
Dr. Jason Rambach, coordinator of the EU Horizon Project HumanTech co-organized a workshop on “AI and Robotics in Construction” at the European Robotics Forum 2023 in Odense, Denmark (March 14th to 16th, 2023) in cooperation with the construction Robotics projects Beeyonders and RobetArme.
From the project HumanTech, Jason Rambach presented an overview of the project objectives as well as insights into the results achieved by Month 9 of the project. Patrick Roth from the partner Implenia, presented the perspective and challenges of the construction industry on the use of Robotics and AI in construction sites, while the project partners Dr. Bharath Sankaran (Naska.AI) and Dr. Gabor Sziebig (SINTEF) participated in a panel session discussing the future of Robotics in construction.
The kick-off meeting for the EU project ExtremeXP was held on January 26th and 27th, 2023, in the city of Athens, Greece.
The vision of ExtremeXP “EXPerimentation driven and user eXPerience-oriented analytics for eXtremely Precise outcomes and decisions” is to provide accurate, precise, fit-for-purpose, and trustworthy data-driven insights via evaluating different complex analytics variants, considering end users’ preferences and feedback in an automated way.
Dr. Alain Pagani enlightened the audience on the capabilities of the Augmented Vision department, highlighting the expertise and key strengths it brings to the table in the realm of Augmented Reality and Explainability.
ExtremeXP will provide:
Specification and semantics for modelling complex user-experience-driven analytics.
Automated and scalable data management for complex analytics workflow.
Scenario-driven and opportunistic machine learning to design and develop AutoML mechanisms for performing scenario-based algorithm and model selection considering on-demand user-provided constraints (performance, resources, time, model options).
User-experience- and experiment-driven optimization of complex analytics to design the architecture of the framework for experiment-driven optimisation of complex analytics.
Transparent decision making with interactive visualisation methods to explore how augmented reality, visual analytics, and other visualisation techniques and their combinations can enhance user experience for different use cases, actors, domains, applications, and problem areas
Extreme data access control and knowledge management
Test and validation framework and application on different impactful real-life use cases to incorporate the ExtremeXP tools, methods, models, and software into a scalable, usable, and interoperable integrated framework for complex experiment-driven analytics
The project consortium consists of 20 partners, which are:
Athena Research Center (coordinator) [Greece]
Activeeon [France]
Airbus Defense and Spaces SLC [France]
BitSparkles [France]
Bournemouth University [United Kingdom]
CS-Group [France]
Charles University of Prague [Czech Republic]
Deutsches Forschungszentrum für Künstliche Intelligenz [Germany]
Fundacio Privada I2cat, Internet I Innovacio Digital A Catalunya [Spain]
Institute of Communications and Computer Systems [Greece]
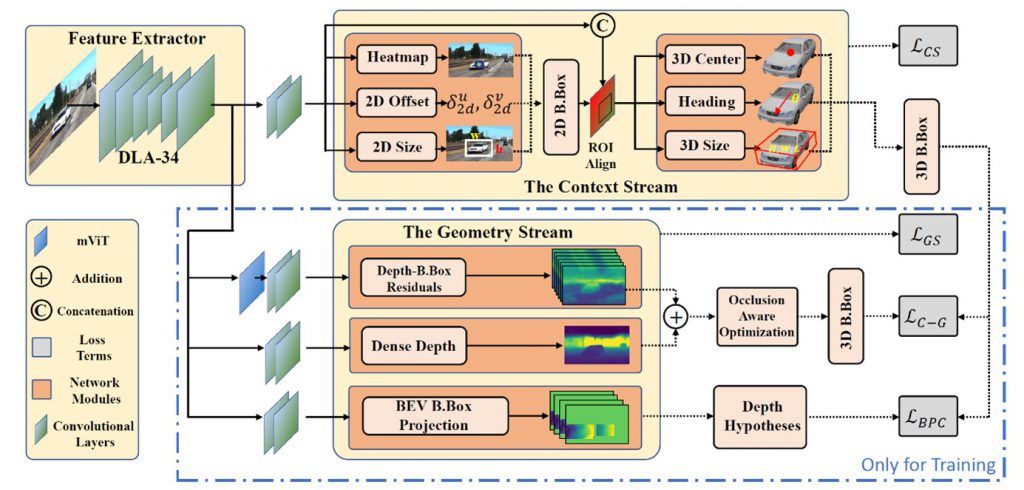
We are happy to announce that our article “OPA-3D: Occlusion-Aware Pixel-Wise Aggregation for Monocular 3D Object Detection” was published in the prestigious IEEE Robotics and Automation Letters (RA-L) Journal. The work is a collaboration of DFKI with the TU Munich and Google. The article is openly accessible at: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10021668
Abstract: Monocular 3D object detection has recently made a significant leap forward thanks to the use of pre-trained depth estimators for pseudo-LiDAR recovery. Yet, such two-stage methods typically suffer from overfitting and are incapable of explicitly encapsulating the geometric relation between depth and object bounding box. To overcome this limitation, we instead propose to jointly estimate dense scene depth with depth-bounding box residuals and object bounding boxes, allowing a two-stream detection of 3D objects that harnesses both geometry and context information. Thereby, the geometry stream combines visible depth and depth-bounding box residuals to recover the object bounding box via explicit occlusion-aware optimization. In addition, a bounding box based geometry projection scheme is employed in an effort to enhance distance perception. The second stream, named as the Context Stream, directly regresses 3D object location and size. This novel two-stream representation enables us to enforce cross-stream consistency terms, which aligns the outputs of both streams, and further improves the overall performance. Extensive experiments on the public benchmark demonstrate that OPA-3D outperforms state-of-the-art methods on the main Car category, whilst keeping a real-time inference speed.
DFKI Augmented Vision recently released the first publicly available UWB Radar Driving Activity Dataset (RaDA), consisting of over 10k data samples from 10 different participants annotated with 6 driving activities. The dataset was recorded in the DFKI driving simulator environment. For more information and to download the dataset please check the project website: https://projects.dfki.uni-kl.de/rada/
The dataset release is accompanied by an article publication at the Sensors journal:
On Thursday, October 27th, 2022, Mohamed Selim successfully defended his PhD thesis entitled “Deep Learning-based Head Orientation and Gender Estimation from Face Image” in front of the the PhD committee consisting of Prof. Dr. Didier Stricker (TU Kaiserslautern), Prof. Dr. Karsten Berns (TU Kaiserslautern), and Prof Dr. Stefan Deßloch (TU Kaiserslautern).
In the thesis, Mohamed Selim studied the problem of gender and head orientation estimation from face images. Machine-based perception can be of great benefit in extracting that underlying information in face images if the problem is properly modeled. In his thesis, novel solutions are provided to the problems of head orientation estimation and gender prediction. Moreover, the effect of facial appearance changes due to head orientation variation has been investigated on gender prediction accuracy. A novel orientation-guided feature maps recalibration method is presented, that significantly increased the accuracy of gender prediction.
Mohamed Selim received his bachelor and master’s degrees in Computer Science and Engineering from the German University in Cairo, Egypt. He joined the Augmented Vision department in October 2012, as a PhD candidate, and later in March 2018 as a researcher working on industrial and EU research projects. His research interests include computer vision, 3D reconstruction, and deep learning.
Mr. Selim after his successful PhD defense
A week later, on Friday, November 4th, 2022, MSc. Ing. Hammad Tanveer Butt also successfully defended his PhD thesis entitled “Improved Sensor Fusion and Deep Learning of 3D Human Pose From Sparse Magnetic Inertial Measurement Units” in front of the PhD committee consisting of Prof. Dr. Didier Stricker (TU Kaiserslautern and DFKI), Prof. Dr. Imran Shafi (National University of Sciences and Technology, Pakistan) and Prof. Dr. Jörg Dörr (TU Kaiserslautern and IESE Fraunhofer).
The goal of the thesis was to obtain a magnetometer robust 3D human body pose from sparse magnetic inertial motion sensors with uncertainty prediction employing Bayesian Deep learning. To this end, a systematic approach was adopted to address all the challenges of inertial motion capture in an end to end manner. First, simultaneous calibration of multiple magnetic inertial sensors was achieved with error mitigation and residual uncertainty learning. Then a magnetometer robust sensor fusion algorithm for 3D orientation was proposed. Adaptive anatomical error correction was used to reduce long term drift in the joint angles.
Also joint angle constraints were learned using a data driven approach while employing swing-twist formulation for 3D joint rotations. Finally, the thesis showed that Bayesian deep learning framework can be used to learn 3D human pose from sparse magnetic inertial sensors while also predicting the uncertainty of pose estimation which is well correlated with actual error and lack of information, particularly when the yaw angle derived from magnetometer is not used. The thesis led to two peer-reviewed contributions in IEEE Access Journal, as well as a best scientific paper award in IntelliSys-2019 Conference held at UK. The conference paper on swing-twist learning of joint constraints presented in Machine Vision Applications (MVA)-2019, Tokyo Japan was later invited by the reviewing committee amongst top-candidates to be published as a journal paper (extended version). A conference paper and a poster by the author were also accepted at FUSION-2019 Conference held at Ottawa, Canada.
MSc. Ing. Hammad Tanveer Butt received his Bachelors in Avionics (1999) and Master degree in Electrical Engineering (2013) from National University of Sciences and Technology (NUST) Pakistan, respectively. From 2016-2021, he worked at the Augmented Vision (AV) group DFKI as a researcher, while pursuing his PhD. His research interests include nano-electronics, MEMS sensors, deep learning/AI and quantum machine learning.
The kick-off meeting of the CORTEX² project has been held at DFKI in Kaiserslautern on September 20th, 2022.
Participants at the kick-off meeting in Kaiserslautern
The mission of CORTEX² “COoperative Real-Time EXperiences with EXtended reality” is to democratize access to the remote collaboration offered by next-generation XR experiences across a wide range of industries and SMEs.
CORTEX2 will provide:
Full support for AR experience as an extension of video conferencing systems when using heterogeneous service end devices through a novel Mediation Gateway platform.
Resource-efficient teleconferencing tools through innovative transmission methods and automatic summarization of shared long documents.
Easy-to-use and powerful XR experiences with instant 3D reconstruction of environments and objects, and simplified use of natural gestures in collaborative meetings.
Fusion of vision and audio for multichannel semantic interpretation and enhanced tools such as virtual conversational agents and automatic meeting summarization.
Full integration of internet of things (IoT) devices into XR experiences to optimize interaction with running systems and processes.
Optimal extension possibilities and broad adoption by delivering the core system with open APIs and launching open calls to enable further technical extensions, more comprehensive use cases, and deeper evaluation and assessment.
Partners of the project are:
DFKI – Deutsches Forschungszentrum für Künstliche Intelligenz GmbH Germany
LINAGORA – France
ALE – Alcatel-Lucent Entreprise International France
ICOM – Intracom SA Telecom Solutions Greece
AUS – AUSTRALO Alpha Lab MTÜ Estonia
F6S – F6S Network Limited Ireland
KUL– Katholieke Universiteit Leuven Belgium
CEA – Commissariat à l’énergie atomique et aux énergies alternatives France
ACT – Actimage GmbH Germany
UJI – Universitat Jaume I De Castellon
In addition to the project activities, CORTEX² will invest a total of 4 million Euros in two open calls, which will be aimed at recruiting tech startups/SMEs to co-develop CORTEX2; engaging new use-cases from different domains to demonstrate CORTEX2 replication through specific integration paths; assessing and validating the social impact associated with XR technology adoption in internal and external use cases.