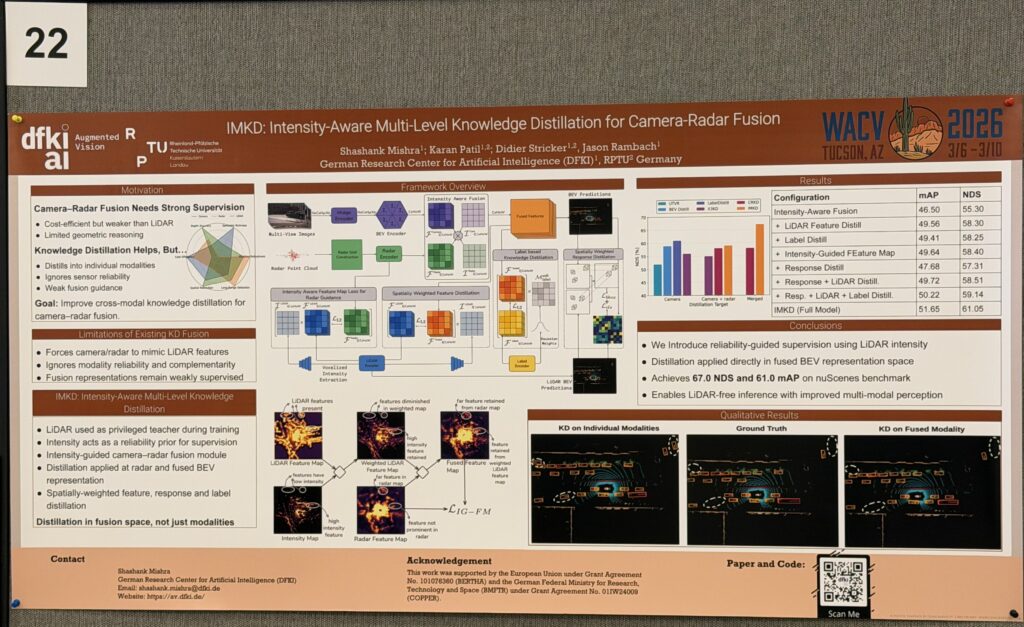
The paper connects the real-world problem of evolving class sets to AI-based document layout analysis.
Special recognition goes to Nick Jochum for carrying out the thesis work that formed the foundation of this publication, as well as to Insiders Technologies for the valuable collaboration.
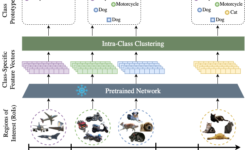
The paper presents results of our collaboration with the Islamic University of Gaza on sensor fusion for 3D scene flow estimation. Our work has received the Emerging Research Award, highlighting the quality of the presented paper.
The Computer Vision Conference 2026 took place in Amsterdam, NL, from May 21st to 22nd.
The Augmented Vision department has 3 papers accepted at the upcoming ICPR 2026 conference. The conference will be taking place at the International Convention Center, Lyon, France, from August 17th to 22nd. The accepted papers are:
Several researchers of the Augmented Vision department have recently received prestigious reviewer awards from the leading computer vision and machine learning conferences.
4 AV members (Dr. Jason Rambach, Dr. Alain Pagani, Shaoxiang Wang and Yaxu Xie) have received the Outstanding Reviewer of the CVPR 2026 conference, given to the top 6.1% out of 25.149 reviewers. The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) is the premier annual computer vision event. CVPR 2026 will be held in Denver, CO, from June 3rd to 7th, 2026.
The complete list of outstanding reviewers for this year can be accessed HERE
In addition, Shashank Mishra has received the Gold Reviewer award of the ICML conference, given to the top 25% reviewers. The International Conference on Machine Learning (ICML) is the premier Machine Learning conference world-wide. ICML 2026 will be held Seoul, South Korea, from July 6th to 11th, 2026.
The workshop included presentations on the current state of 6 EU Horizon projects on construction robotics (Beeyonders, RobetArme, ShieldBoT, Target-X, XSCAVE, DISCOVER), followed by a round table and interactive session with the audience on the challenges and opportunities of robotic projects in construction.
The department Augmented Vision has 4 accepted papers at the upcoming CVPR 2026 conference taking place from June 3-7, 2026 at the Colorado Convention Center, Denver, USA.
The CVPR conference is the premier international conference in computer vision and pattern recognition.
We are happy to anounce that our work on sensor generalization has won a Best Paper Award at ICPRAM 2026. The conference was held in Marbella, Spain, from March 2nd to 4th.
The Network of Excellence dAIEDGE organized two strategic workshops at the High Performance Embedded Architectures and Compilers Conference HiPEAC 2026, which took place in Krakow, Poland from January 26 to 28. The events brought together leading researchers, industry representatives and European initiatives to discuss the future of distributed, autonomous and trustworthy edge AI systems.
The workshop “The Intelligent Mesh: Edge AI Technology Roadmap for Orchestrating Autonomous Systems with Agentic and Generative AI”, co-organized by Ovidiu Vermesan from SINTEF, Alain Pagani from DFKI, Marcello Coppola from ST Microelectronics and Fabian Chersi from CEA, focused on the next generation of edge AI architectures. Discussions addressed heterogeneous hardware platforms, edge accelerators, neuromorphic approaches and optimized AI frameworks, as well as Small Language Models and Vision Language Models tailored for embedded systems. A central theme was agentic AI at the edge and the vision of an intelligent mesh of autonomous systems capable of collaboration and orchestration. The workshop contributed to shaping a European roadmap for secure, sovereign and scalable edge AI.
The second workshop, “Sustainable and Trustworthy Edge AI for Robotics”, was co-organized by the Networks of Excellence dAIEDGE, euROBIN, ELIAS and ENFIELD. It featured keynote talks by Maximilian Durner from DLR, Jean Marc Bonnefous from TCS, Georgios Spathoulas from NTNU and Eyup Kun from KU Leuven, and included two technical sessions on efficient, regulation-aware and human-centered AI for robotic systems. The workshop concluded with a panel discussion moderated by Alain Pagani on aligning European lighthouse strategies for sustainable, trustworthy and efficient AI.
Together, the two workshops highlighted dAIEDGE’s leading role in fostering collaboration across European AI networks and in advancing a coordinated strategy for next generation edge intelligence.
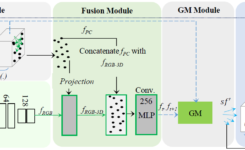
We are glad to announce that our paper, NURBGen: High-Fidelity Text-to-CAD Generation through LLM-Driven NURBS Modeling, has been accepted at the Fortieth AAAI Conference on Artificial Intelligence (AAAI) 2026 Singapore. Co-led by Muhammad Sadil Khan and Muhammad Usama under the supervision of Didier Stricker and Muhammad Zeshan Afzal, our research introduces the first framework to generate high-fidelity, editable 3D CAD models directly from text by fine-tuning a large language model to produce structured NURBS surface parameters. To overcome the limitations of existing mesh-based or design-history systems, we propose a hybrid symbolic representation that combines untrimmed NURBS with analytic primitives to robustly handle trimmed surfaces and degenerate regions while maintaining token efficiency. Evaluated on our new partABC dataset of 300k annotated CAD components, NURBGen demonstrates strong performance in geometric fidelity and dimensional accuracy, as confirmed by expert evaluations.
On 16 January 2026, Mohammad Minouei successfully defended his PhD entitled ‘Structural Information Extraction from Document Images: Addressing Challenges in Layout Analysis, Table Detection, and Classification’.
The doctoral thesis was carried out in the Augmented Vision department at DFKI under the supervision of Prof. Dr. Didier Stricker.
The examination committee consisted of Prof. Dr. Didier Stricker (RPTU), Prof. Dr. Faisal Shafait (NUST) and Prof. Dr. Leo Van Waveren (RPTU).
Die EU hat am 10. Dezember in Brüssel die „European Partnership for Virtual Worlds“ lanciert – und das DFKI ist von Anfang an dabei! Über die Virtual Worlds Association (VWA) bringen wir unsere KI-Expertise für Extended Reality, Simulation und industrielle Anwendungen ein. Prof. Dr. Didier Stricker prägt als Board-Mitglied die Strategie.
„KI ist die Schlüsseltechnologie für virtuelle Welten – sie macht XR erlebbar und beschleunigt Prozesse durch realistische Digital Twins“, betont Stricker.
The AV-team consisting of Ahmed Tawfik Aboukhadra, Marcel Rogge, Nadia Robertini, Ahmed Elhayek, Abdalla Arafa, Jameel Malik, and Didier Stricker, has been awarded 1st place in the 9th “Observing and Understanding Hands” (ARCTIC) Workshop Challenge, held in conjunction with ICCV 2025. The team presented their winning solution during the workshop program on the 20th October 2025, showcasing their innovative approach to bimanual hand–object reconstruction.
Their method, “GHOST: Gaussian Hand–Object Surface Reconstruction with Geometric Priors,” introduces a highly efficient framework that reconstructs animatable hand avatars and category-agnostic objects from monocular RGB videos. The approach enables realistic hand–object interactions and significantly outperforms previous state-of-the-art methods both qualitatively and quantitatively, while achieving a 13x speed-up over existing techniques.
This achievement marks an important step forward in human motion understanding, opening promising avenues for applications in Virtual Reality (VR) and Augmented Reality (AR).
Elgoibar (Spain), 20 November 2025 – The ShieldBot project – Next-Generation Robotics for Sustainable and Efficient Thermal Shielding of Buildings – officially launched with a kick-off meeting on 4-5 of November 2025 at the premises of IDEKO Research Centre, the project coordinator, in Elgoibar (Basque Country), Spain.
Funded by the Horizon Europe programme with EUR 4 million and set to run over three years, ShieldBot brings together 11 partners from six European countries. The consortium ambitions to revolutionise how buildings are constructed, renovated, and maintained through the use of advanced, sustainable robotics.
In response to Europe’s growing demand for energy-efficient and sustainable buildings, ShieldBot aims to bridge the gap between traditional construction methods and modern sustainability standards. The project will develop and validate a new generation of robotic systems specifically designed for the construction, renovation, and maintenance of buildings, enabling greater efficiency, safety, and environmental performance.
At its core, ShieldBot focuses on three key robotic platforms: Façade-ShieldBot, which installs thermal shielding on building façades to improve insulation and reduce energy consumption; Inner-ShieldBot, designed for internal construction work to enhance the thermal performance of walls and ceilings, and Inspection-ShieldBot, equipped with advanced sensors to assess exteriors, identify structural or insulation needs, and ensure long-term building integrity.
These robotic systems are supported by Digi-Shield, a digital twin platform that aggregates and analyses data from on-site operations, enabling real-time decision-making and precise project planning. Moreover, the use of Eco-Shield materials, innovative, eco-friendly insulation solutions, will further minimise the carbon footprint of construction activities.
ShieldBot’s vision extends beyond automation. A strong emphasis is placed on human–robot collaboration, ensuring that technology complements human expertise rather than replacing it. This synergy will enhance workforce safety, productivity, and efficiency, while supporting the transition towards greener and smarter construction processes.
The project’s activities will be structured across three main research areas: disruptive robotic solutions for the construction industry, advanced robot functionalities for construction and renovation works, and advanced construction site technologies. In the context of these research areas, three demonstration cases will be carried out: interior wall and ceiling construction in office buildings, inspection and maintenance of exterior building façades, and exterior façade insulation of multi-family dwellings.
By combining cutting-edge robotics, artificial intelligence, and sustainable materials, ShieldBot will set a new benchmark for efficiency and environmental responsibility in construction. The project’s outcomes are expected to contribute significantly to the European Green Deal’s objectives and the broader digital and green transformation of the built environment.
At the European Conference on Edge AI Technologies and Applications (EEAI 2025), held in Naples on October 22nd-24th, Dr. Alain Pagani from DFKI’s Augmented Vision department moderated the panel “Future Edge AI Technologies and Applications: Trends and Development Landscape.”
The session gathered key experts from leading European projects and organisations — SINTEF, CNIT, TTTech Auto, Eclipse Foundation, EXAPSYS, Technical University of Crete, and STMicroelectronics — to discuss how Europe can strengthen its innovation ecosystem, bridge the skills gap, and advance open, sovereign Edge AI technologies.
The discussion reflected the shared goals of dAIEDGE, the Network of Excellence on Edge AI coordinated by DFKI.
On Ocotober 27th, 2025 Michael David Fürst successfully defended his doctoral thesis entitled “Fusion in Object Detection and Human Pose Estimation for Automotive Scene Understanding”.
The PhD thesis was carried out in the Augmented Vision department at DFKI, supervised by Prof. Dr. Didier Stricker.
The PhD examination commission consisted of Prof. Dr. Didier Stricker (RPTU), Prof. Dr. Jörg Dörr (RPTU), Prof. Dr. Carlo Alberto (School of Advanced Studies, Pisa).
Congratulations on your PhD and we wish you all the best for the future!
Sai Srinivas Jeevanandam represented DFKI Augmented Vision at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025), held in Hangzhou, China from October 19 to 25 and presented the paper:



























{kind=link}