We are happy to announce that the Augmented Vision group will present two papers in the upcoming CVPR 2022 Conference from June 19th-23rd in New Orleans, USA. The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) is the premier annual computer vision event internationally. Homepage: https://cvpr2022.thecvf.com/
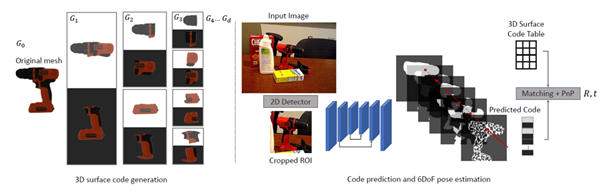
Summary: ZebraPose sets a new paradigm on model-based 6DoF object pose estimation by using a binary object surface encoding to train a neural network to predict the locations of model vertices in a coarse to fine manner. ZebraPose shows a major improvement over the state-of-the-art on several datasets of the BOP Object Pose Estimation benchmark.
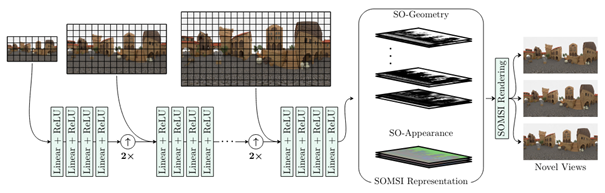
Summary: We propose a novel Multi-Sphere Image representation called Soft Occlusion MSI (SOMSI) and efficient rendering technique that produces accurate spherical novel-views from a sparse spherical light-field. SOMSI models appearance features in a smaller set (e.g. 3) of occlusion levels instead of larger number (e.g. 64) of MSI spheres. Experiments on both synthetic and real-world spherical light-fields demonstrate that using SOMSI can provide a good balance between accuracy and run-time. SOMSI view synthesis quality is on-par with state-of-the-art models like NeRF, while being 2 orders of magnitude faster.
We are happy to announce that the Augmented Vision group will present 2 papers in the upcoming BMVC 2021 Conference, 22-25 November, 2021:
The British Machine Vision Conference (BMVC) is the British Machine Vision Association (BMVA) annual conference on machine vision, image processing, and pattern recognition. It is one of the major international conferences on computer vision and related areas held in the UK. With increasing popularity and quality, it has established itself as a prestigious event on the vision calendar. Homepage: https://www.bmvc2021.com/
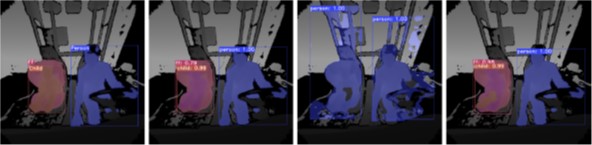
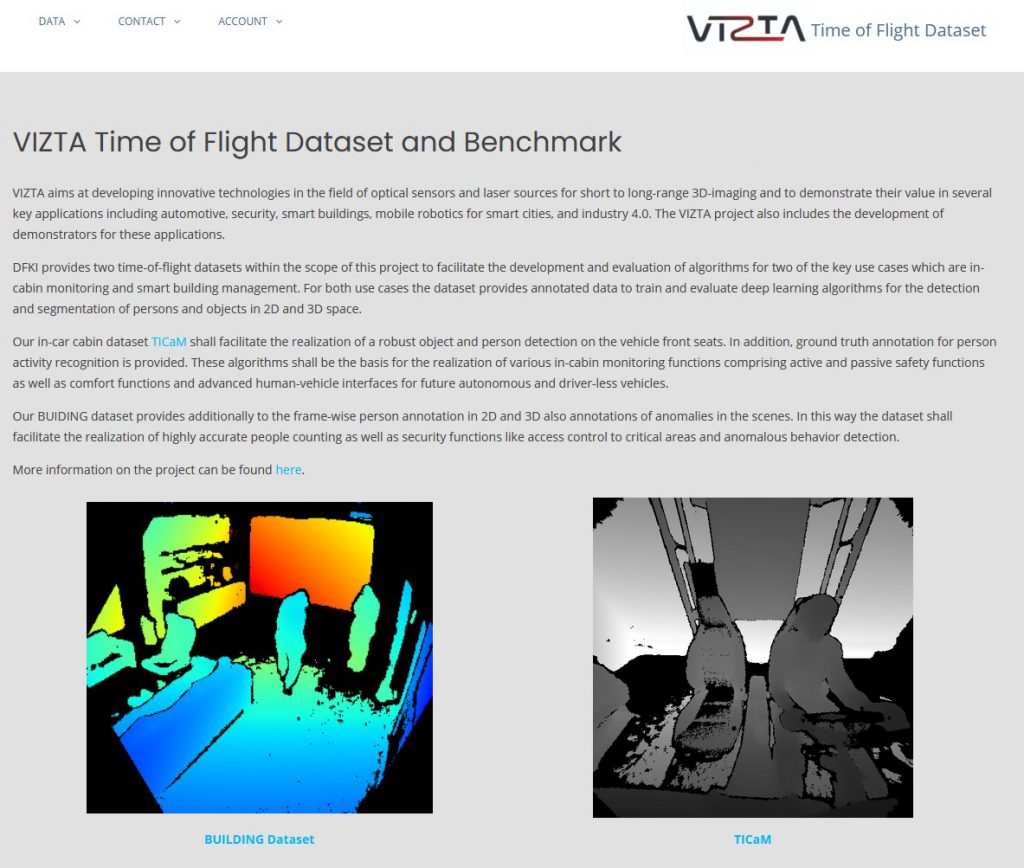
Summary: TICaM is a Time-of-flight In-car Cabin Monitoring dataset for vehicle interior monitoring using a single wide-angle depth camera. The dataset goes beyond currently available in-car cabin datasets in terms of the ambit of labeled classes, recorded scenarios and annotations provided; all at the same time. The dataset is available here: https://vizta-tof.kl.dfki.de/
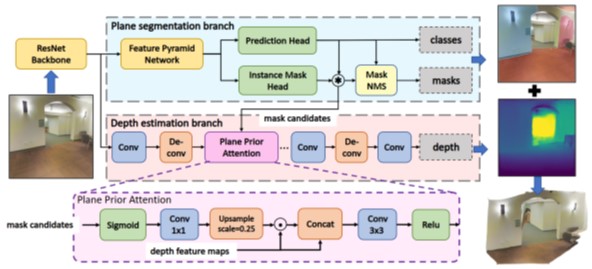
Summary: Piece-wise 3D planar reconstruction provides holistic scene understanding of man-made environments, especially for indoor scenarios. Different from other existing approaches, we start from enforcing cross-task consistency for our multi-task convolutional neural network, PlaneRecNet, which integrates a single-stage instance segmentation network for piece-wise planar segmentation and a depth decoder to reconstruct the scene from a single RGB image.
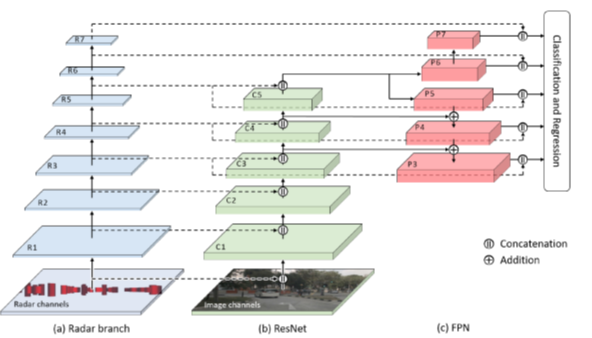
DFKI Augmented Vision is working with Stellantis on the topic of Radar-Camera Fusion for Automotive Object Detection using Deep Learning since 2020. The collaboration has already led to two publications, in ICCV 2021 (International Conference on Computer Vision – ERCVAD Workshop on “Embedded and Real-World Computer Vision in Autonomous Driving”) and WACV 2022 (Winter Conference on Applications of Computer Vision).
The 2 publications are:
1. Deployment of Deep Neural Networks for Object Detection on Edge AI Devices with Runtime Optimization, Proceedings of the IEEE International Conference on Computer Vision Workshops – ERCVAD Workshop on Embedded and Real-World Computer Vision in Autonomous Driving
This paper discusses the optimization of neural network based algorithms for object detection based on camera, radar, or lidar data in order to deploy them on an embedded system on a vehicle.
2. Fusion Point Pruning for Optimized 2D Object Detection with Radar-Camera Fusion, Proceedings of the IEEE Winter Conference on Applications of Computer Vision, 2022
This paper introduces fusion point pruning, a new method to optimize the selection of fusion points within the deep learning network architecture for radar-camera fusion.
As part of the research activities of DFKI Augmented Vision in the VIZTA project (https://www.vizta-ecsel.eu/), two publicly available datasets have been released and are available for download. TIMo dataset is a building indoor monitoring dataset for person detection, person counting, and anomaly detection. TICaM dataset is an automotive in-cabin monitoring dataset with a wide field of view for person detection and segmentation and activity recognition. Real and synthetic images are provided allowing for benchmarking of transfer learning algorithms as well. Both datasets are available here https://vizta-tof.kl.dfki.de/. The publication describing the datasets in detail are available as preprints.
On July 29th, 2021, Dr. Jason Rambach presented the survey paper “A Survey on Applications of Augmented, Mixed and Virtual Reality for Nature and Environment” at the 23rd Human Computer Interaction Conference HCI International. The article is the result of a collaboration between DFKI, the Worms University of Applied Sciences and the University of Kaiserslautern.
Abstract: Augmented, virtual and mixed reality (AR/VR/MR) are technologies of great potential due to the engaging and enriching experiences they are capable of providing. However, the possibilities that AR/VR/MR offer in the area of environmental applications are not yet widely explored. In this paper, we present the outcome of a survey meant to discover and classify existing AR/VR/MR applications that can benefit the environment or increase awareness on environmental issues. We performed an exhaustive search over several online publication access platforms and past proceedings of major conferences in the fields of AR/VR/MR. Identified relevant papers were filtered based on novelty, technical soundness, impact and topic relevance, and classified into different categories. Referring to the selected papers, we discuss how the applications of each category are contributing to environmental protection and awareness. We further analyze these approaches as well as possible future directions in the scope of existing and upcoming AR/VR/MR enabling technologies.
DFKI participates in the VIZTA project, coordinated by ST Micrelectronics, aiming at developing innovative technologies in the field of optical sensors and laser sources for short to long-range 3D-imaging and to demonstrate their value in several key applications including automotive, security, smart buildings, mobile robotics for smart cities, and industry 4.0. The 24-month review by the EU-commission was completed and a public summary of the project was released, including updates from DFKI Augmented Vision on time-of-flight camera dataset recording and deep learning algorithm development for car in-cabin monitoring and smart building person counting and anomaly detection applications.
Abstract: The
problem of semantic segmentation from depth images can be addressed by segmenting
directly in the image domain or at 3D point cloud level. In this paper, we
attempt for the first time to provide a study and experimental comparison of the
two approaches. Through experiments on three datasets, namely SUN RGB-D, NYUdV2
and TICaM, we extensively compare various semantic segmentation algorithms, the
input to which includes images and point clouds derived from them. Based on
this, we offer analysis of the performance and computational cost of these
algorithms that can provide guidelines on when each method should be preferred.
As part of the research activities of DFKI Augmented Vision in the VIZTA project (https://www.vizta-ecsel.eu/), we have published the open-source dataset for automotive in-cabin monitoring with a wide-angle time-of-flight depth sensor. The TiCAM dataset represents a variety of in-car person behavior scenarios and is annotated with 2D/3D bounding boxes, segmentation masks and person activity labels. The dataset is available here https://vizta-tof.kl.dfki.de/. The publication describing the dataset in detail is available as a preprint here: https://arxiv.org/pdf/2103.11719.pdf
Abstract: Instance segmentation of planar regions in indoor scenes benefits visual SLAM and other applications such as augmented reality (AR) where scene understanding is required. Existing methods built upon two-stage frameworks show satisfactory accuracy but are limited by low frame rates. In this work, we propose a real-time deep neural architecture that estimates piece-wise planar regions from a single RGB image. Our model employs a variant of a fast single-stage CNN architecture to segment plane instances. Considering the particularity of the target detected, we propose Fast Feature Non-maximum Suppression (FF-NMS) to reduce the suppression errors resulted from overlapping bounding boxes of planes. We also utilize a Residual Feature Augmentation module in the Feature Pyramid Network (FPN) . Our method achieves significantly higher frame-rates and comparable segmentation accuracy against two-stage methods. We automatically label over 70,000 images as ground truth from the Stanford 2D-3D-Semantics dataset. Moreover, we incorporate our method with a state-of-the-art planar SLAM and validate its benefits.
DFKI participates in the VIZTA project, coordinated by ST Micrelectronics, aiming at developing innovative technologies in the field of optical sensors and laser sources for short to long-range 3D-imaging and to demonstrate their value in several key applications including automotive, security, smart buildings, mobile robotics for smart cities, and industry4.0. The 18-month public summary of the project was released, including updates from DFKI Augmented Vision on time-of-flight camera dataset recording and deep learning algorithm development for car in-cabin monitoring and smart building person counting and anomaly detection applications.
Please click here to check out the complete summary.
We are excited to announce that the Augmented Vision group will present 3 papers in the upcoming VISAPP 2021 Conference, February 8th-10th, 2021:
The International
Conference on Computer Vision Theory and Applications (VISAPP) is part of
VISIGRAPP, the 16th International Joint Conference on Computer Vision, Imaging
and Computer Graphics Theory and Applications. VISAPP aims at becoming a major
point of contact between researchers, engineers and practitioners on the area
of computer vision application systems. Homepage: http://www.visapp.visigrapp.org/
We are happy to announce
that our paper “SynPo-Net–Accurate and Fast
CNN-Based 6DoF Object Pose Estimation Using Synthetic Training” has been
accepted for publication at the MDPI Sensors journal, Special Issue Object
Tracking and Motion Analysis. Sensors (ISSN 1424-8220; CODEN: SENSC9)
is the leading international peer-reviewed open access journal on the science and technology of sensors.
Abstract: Estimation and
tracking of 6DoF poses of objects in images is a challenging problem of great
importance for robotic interaction and augmented reality. Recent approaches
applying deep neural networks for pose estimation have shown encouraging
results. However, most of them rely on training with real images of objects
with severe limitations concerning ground truth pose acquisition, full coverage
of possible poses, and training dataset scaling and generalization capability.
This paper presents a novel approach using a Convolutional Neural Network (CNN)
trained exclusively on single-channel Synthetic images of objects to regress
6DoF object Poses directly (SynPo-Net). The proposed SynPo-Net is a network
architecture specifically designed for pose regression and a proposed domain
adaptation scheme transforming real and synthetic images into an intermediate
domain that is better fit for establishing correspondences. The extensive
evaluation shows that our approach significantly outperforms the
state-of-the-art using synthetic training in terms of both accuracy and speed.
Our system can be used to estimate the 6DoF pose from a single frame, or be
integrated into a tracking system to provide the initial pose.
The Winter Conference on Applications of Computer Vision (WACV 2021) is IEEE’s and the PAMI-TC’s premier meeting on applications of computer vision. With its high quality and low cost, it provides an exceptional value for students, academics and industry researchers. In 2021, the conference is organized as a virtual online event from January 5th till 9th, 2021.
Abstract: This paper demonstrates a system capable of combining a sparse, indirect, monocular visual SLAM, with both offline and real-time Multi-View Stereo (MVS) reconstruction algorithms. This combination overcomes many obstacles encountered by autonomous vehicles or robots employed in agricultural environments, such as overly repetitive patterns, need for very detailed reconstructions, and abrupt movements caused by uneven roads. Furthermore, the use of a monocular SLAM makes our system much easier to integrate with an existing device, as we do not rely on a LiDAR (which is expensive and power consuming), or stereo camera (whose calibration is sensitive to external perturbation e.g. camera being displaced). To the best of our knowledge, this paper presents the first evaluation results for monocular SLAM, and our work further explores unsupervised depth estimation on this specific application scenario by simulating RGB-D SLAM to tackle the scale ambiguity, and shows our approach produces econstructions that are helpful to various agricultural tasks. Moreover, we highlight that our experiments provide meaningful insight to improve monocular SLAM systems under agricultural settings.
Abstract: Images recorded during the lifetime of computer vision based systems undergo a wide range of illumination and environmental conditions affecting the reliability of previously trained machine learning models. Image normalization is hence a valuable preprocessing component to enhance the models’ robustness. To this end, we introduce a new strategy for the cost function formulation of encoder-decoder networks to average out all the unimportant information in the input images (e.g. environmental features and illumination changes) to focus on the reconstruction of the salient features (e.g. class instances). Our method exploits the availability of identical sceneries under different illumination and environmental conditions for which we formulate a partially impossible reconstruction target: the input image will not convey enough information to reconstruct the target in its entirety. Its applicability is assessed on three publicly available datasets. We combine the triplet loss as a regularizer in the latent space representation and a nearest neighbour search to improve the generalization to unseen illuminations and class instances. The importance of the aforementioned post-processing is highlighted on an automotive application. To this end, we release a synthetic dataset of sceneries from three different passenger compartments where each scenery is rendered under ten different illumination and environmental conditions: https://sviro.kl.dfki.de