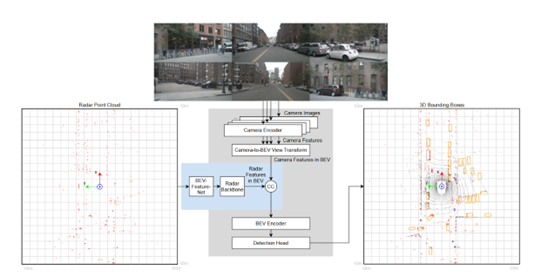
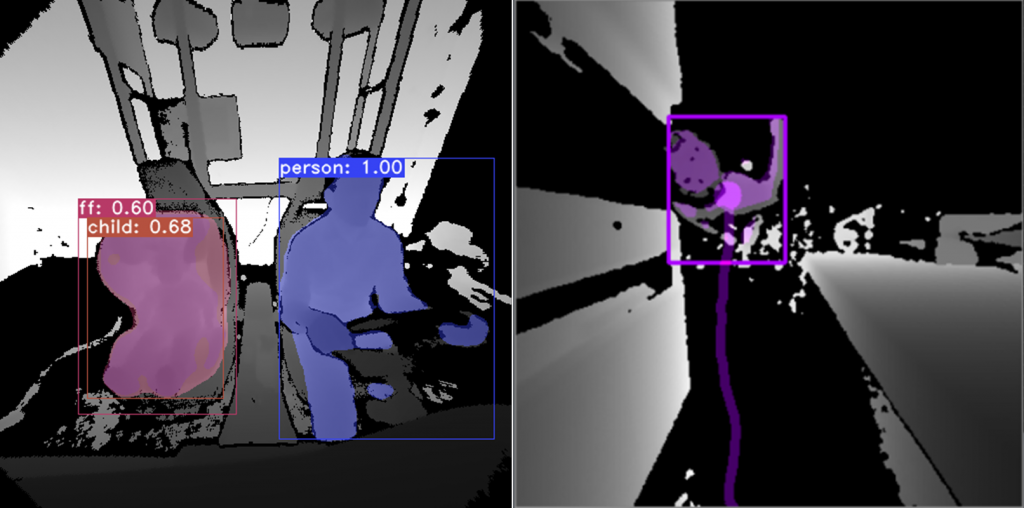
The paper introduces a simplified and improved extrinisic calibration approach for camera-radar systems without the need for external sensing and with additional optimization constraints for added robustness.
DFKI Augmented Vision presented 3 other papers at ICPRAM 2024.
The HumanTech project, coordinated by DFKI Augmented Vision – Dr. Jason Rambach, has reached an important milestone: A highly successfully Mid-Term Review Meeting!
From 22 to 24 January 2024, representatives from the 21 partner organisations that comprise the consortium gathered in Zurich, Switzerland (hosted by the partner Implenia) to comprehensively review its midterm progress since starting in June 2022. The process has helped the consortium to align priorities to further its mission — to achieve breakthroughs in cutting-edge technologies, contributing to a safer, more efficient and digitized European construction industry. The review meeting consisted of a construction site visit, presentations of the project progress for all work packages and an exciting demo event with live HumanTech technologies.
We are happy to announce that the Augmented Vision group presented 2 papers in the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) that took place from the 4th -8th January 2024 in Waikoloa, Hawaii.
The BERTHA project receives EU funding to develop a Driver Behavioral Model that will make autonomous vehicles safer and more human-like
The project, funded by the European Union with Grant Agreement nº 101076360, will receive 7.9 M€ under the umbrella of the Horizon Europe programme.
The BERTHA project will develop a scalable and probabilistic Driver Behavioral Model which will be key to achieving safer and more human-like connected autonomous vehicles, thus increasing their social acceptance. The solution will be available for academia and industry through an open-source data HUB and in the CARLA autonomous driving simulator.
The project’s consortium gathered on 22-24 November for the kick-off meeting, hosted by the coordinator Instituto de Biomecánica de Valencia at its facilities in Spain.
The Horizon Europe project BERTHA kicked off on November 22nd-24th in Valencia, Spain. The project has been granted €7,981,799.50 from the European Commission to develop a Driver Behavioral Model (DBM) that can be used in connected autonomous vehicles to make them safer and more human-like. The resulting DBM will be available on an open-source HUB to validate its feasibility, and it will also be implemented in CARLA, an open-source autonomous driving simulator.
The project celebrated its kick-off meeting on November 22nd to 24th, hosted by the coordinator Instituto de Biomecánica de Valencia (IBV) at its offices in Valencia, Spain. During the event, all partners met each other, shared their technical backgrounds and presented their expected contributions to the project.
The need for a Driver Behavioral Model in the CCAM industry
The industry of Connected, Cooperative, and Automated Mobility (CCAM) presents important opportunities for the European Union. However, its deployment requires new tools that enable the design and analysis of autonomous vehicle components, together with their digital validation, and a common language between Tier vendors and OEM manufacturers.
One of the shortcomings arises from the lack of a validated and scientifically based Driver Behavioral Model (DBM) to cover the aspects of human driving performance, which will allow to understand and test the interaction of connected autonomous vehicles (CAVs) with other cars in a safer and predictable way from a human perspective.
Therefore, a Driver Behavioral Model could guarantee digital validation of the components of autonomous vehicles and, if incorporated into the ECUs software, could generate a more human-like response of such vehicles, thus increasing their acceptance.
The contributions of BERTHA to the autonomous vehicles industry and research
To cover this need in the CCAM industry, the BERTHA project will develop a scalable and probabilistic Driver Behavioral Model (DBM), mostly based on Bayesian Belief Network, which will be key to achieving safer and more human-like autonomous vehicles.
The new DBM will be implemented on an open-source HUB, a repository that will allow industrial validation of its technological and practical feasibility, and become a unique approach for the model’s worldwide scalability.
The resulting DBM will be translated into CARLA, an open-source simulator for autonomous driving research developed by the Spanish partner Computer Vision System. The implementation of BERTHA’s DBM will use diverse demos which allow the building of new driving models in the simulator. This can be embedded in different immersive driving simulators as HAV from IBV.
BERTHA will also develop a methodology which, thanks to the HUB, will share the model with the scientific community to ease its growth. Moreover, its results will include a set of interrelated demonstrators to show the DBM approach as a reference to design human-like, easily predictable, and acceptable behaviour of automated driving functions in mixed traffic scenarios.
Teilnehmer des Kick-Off-Treffens des KIMBA Forschungsvorhabens stehen vor einem mobilen Prallbrecher von Projektpartner KLEEMANN. // Participants of the kick-off meeting of the KIMBA research project standing in front of a mobile impact crusher from project partner KLEEMANN
[Deutsche Version]
Im Rahmen der Digital GreenTech Konferenz 2023 in Karlsruhe wurden kürzlich 14 neue Forschungsprojekte aus den Bereichen Wasserwirtschaft, nachhaltiges Landmanagement, Ressourceneffizienz und Kreislaufwirtschaft vorgestellt, darunter auch Kimba. Hierbei arbeiten wir gemeinsam mit unseren Projektpartnern an einer KI-basierten Prozesssteuerung und automatisiertem Qualitätsmanagement für das Recycling von Bau- und Abbruchabfällen in Echtzeit. Das spart Kosten, Zeit sowie Ressourcen und schont die Umwelt. So unterstützen wir die Baubranche auf ihrem Weg in die Zukunft.
At the Digital GreenTech Conference 2023 in Karlsruhe, 14 new research projects in the fields of water management, sustainable land management, resource efficiency and circular economy were recently presented, including Kimba. Here, we are working with our project partners on AI-based process control and automated quality management for recycling construction and demolition waste in real time. This saves costs, time and resources and protects the environment. This is how we support the construction industry on its way into the future.
Alt-Text: Teilnehmer des Kick-Off-Treffens des ReVise-UP Forschungsvorhabens stehen vor dem Bergbaugebäude der RWTH Aachen University. // Participants of the kick-off meeting of the ReVise-UP research project stand in front of the mining building of RWTH Aachen University.
Deutsche Version
Forschungsvorhaben „ReVise-UP“ zur Verbesserung der Prozesseffizienz des werkstofflichen Kunststoffrecyclings mittels Sensortechnik gestartet
Im September 2023 startete das vom BMBF geförderte Forschungsvorhaben ReVise-UP („Verbesserung der Prozesseffizienz des werkstofflichen Recyclings von Post-Consumer Kunststoff-Verpackungsabfällen durch intelligentes Stoffstrommanagement – Umsetzungsphase“). In der vierjährigen Umsetzungsphase soll die Transparenz und Effizienz des werkstofflichen Kunststoffrecyclings durch Entwicklung und Demonstration sensorbasierter Stoffstromcharakterisierungsmethoden im großtechnischen Maßstab gesteigert werden.
Auf Basis der durch Sensordaten erzeugten Datentransparenz soll das bisherige Kunststoffrecycling durch drei Effekte verbessert werden: Erstens sollen durch die Datentransparenz positive Anreize für verbesserte Sammel- und Produktqualitäten und damit gesteigerte Rezyklatmengen und -qualitäten geschaffen werden. Zweitens sollen sensorbasiert erfasste Stoffstromcharakteristika dazu genutzt werden, Sortier-, Aufbereitungs- und Kunststoffverarbeitungsprozesse auf schwankende Stoffstromeigenschaften adaptieren zu können. Drittens soll die verbesserte Datenlage eine ganzheitliche ökologische und ökonomische Bewertung der Wertschöpfungskette ermöglichen.
Research project “ReVise-UP” started to improve the process efficiency of mechanical plastics recycling using sensor technology
In September 2023, the BMBF-funded research project ReVise-UP (“Improving the process efficiency of mechanical recycling of post-consumer plastic packaging waste through intelligent material flow management – implementation phase”) started. In the four-year implementation phase, the transparency and efficiency of mechanical plastics recycling is to be increased by developing and demonstrating sensor-based material flow characterization methods on an industrial scale.
Based on the data transparency generated by sensor data, the current plastics recycling shall be improved by three effects: First, data transparency is intended to create positive incentives for improved collection and product qualities and thus increased recyclate quantities and qualities. Second, sensor-based material flow characteristics are to be used to adapt sorting, treatment and plastics processing processes to fluctuating material flow properties. Third, the improved data situation should enable a holistic ecological and economic evaluation of the value chain.
DFKI Augmented Vision researchers Praveen Nathan, Sandeep Inuganti, Yongzhi Su and Jason Rambach received their 1st place award in the prestigious BOP Object Pose Estimation Challenge 2023 in the categories Overall Best RGB Method,Overall Best Segmentation Method and The Best BlenderProc-Trained Segmentation Method.
The BOP benchmark and challenge addresses the problem of 6-degree-of-freedom object pose estimation, which is of great importance for many applications such as robot grasping or augmented reality. This year, the BOP challenge was held within the “8th International Workshop on Recovering 6D Object Pose (R6D)” http://cmp.felk.cvut.cz/sixd/workshop_2023/ at the International Conference on Computer Vision (ICCV) in Paris, France https://iccv2023.thecvf.com/ .
The awards were received by Yongzhi Su and Dr. Jason Rambach on behalf of the DFKI Team and a short presentation of the method followed. The winning method was based on the CVPR 2022 paper “ZebraPose”
The winning approach was developed by a team led by DFKI AV, with contributing researchers from Zhejiang University.
List of contributing researchers:
DFKI Augmented Vision: Praveen Nathan, Sandeep Inuganti, Yongzhi Su, Didier Stricker, Jason Rambach
DFKI Augmented Vision is collaborating with Stellantis on the topic of Radar-Camera Fusion for Automotive Object Detection using Deep Learning. Recently, two new publications were accepted to the GCPR 2023 and EUSIPCO 2023 conferences.
The 2 new publications are:
1. Cross-Dataset Experimental Study of Radar-Camera Fusion in Bird’s-Eye View, Proceedings of the 31st. European Signal Processing Conference (EUSIPCO-2023), September 4-8, Helsinki, Finland, IEEE, 2023.
This paper investigates the influence of the training dataset and transfer learning on camera-radar fusion approaches, showing that while the camera branch needs large and diverse training data, the radar branch benefits more from a high-performance radar.
2. RC-BEVFusion: A Plug-In Module for Radar-Camera Bird’s Eye View Feature Fusion, Proceedings of. Annual Symposium of the German Association for Pattern Recognition (DAGM-2023), September 19-22, Heidelberg, BW, Germany, DAGM, 9/2023.
This paper introduces a new Bird’s Eye view fusion network architecture for camera-radar fusion for 3D object detection that performs favorably on the NuScenes dataset benchmark.
We are happy to announce that the Augmented Vision group will present 4 papers in the upcoming ICCV 2023 Conference, 2-6 October, Paris, France. The IEEE/CVF International Conference in Computer Vision (ICCV) is the premier international computer vision event. Homepage: https://iccv2023.thecvf.com/
The 4 accepted papers are:
U-RED: Unsupervised 3D Shape Retrieval and Deformation for Partial Point Clouds Yan Di, Chenyangguang Zhang, Ruida Zhang, Fabian Manhardt, Yongzhi Su, Jason Raphael Rambach, Didier Stricker, Xiangyang Ji, Federico Tombari
Introducing Language Guidance in Prompt-based Continual Learning Muhammad Gulzain Ali Khan, Muhammad Ferjad Naeem; Luc Van Gool; Federico Tombari; Didier Stricker, Muhammad Zeshan Afzal
DELO: Deep Evidential LiDAR Odometry using Partial Optimal Transport Sk Aziz Ali, Djamila Aouada, Gerd Reis, Didier Stricker
On the 18.6, the team presented their solution and results as part of the workshop program. Scan-to-BIM solutions are of great importance for the construction community as they automate the generation of as-built models of buildings from 3D scans, and can be used for quality monitoring, robotic task planning and XR visualization, among other applications.
Dr. Jason Rambach, coordinator of the EU Horizon Project HumanTech co-organized a workshop on “AI and Robotics in Construction” at the European Robotics Forum 2023 in Odense, Denmark (March 14th to 16th, 2023) in cooperation with the construction Robotics projects Beeyonders and RobetArme.
From the project HumanTech, Jason Rambach presented an overview of the project objectives as well as insights into the results achieved by Month 9 of the project. Patrick Roth from the partner Implenia, presented the perspective and challenges of the construction industry on the use of Robotics and AI in construction sites, while the project partners Dr. Bharath Sankaran (Naska.AI) and Dr. Gabor Sziebig (SINTEF) participated in a panel session discussing the future of Robotics in construction.
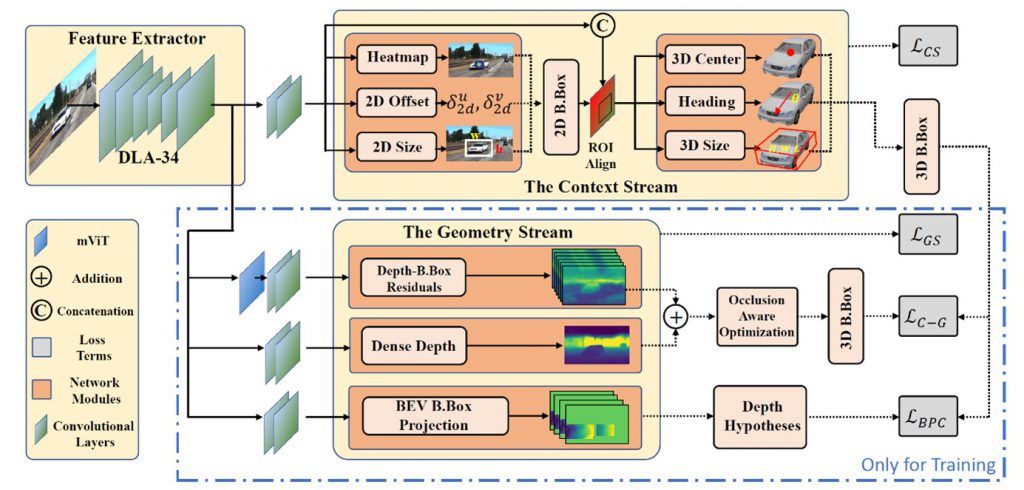
We are happy to announce that our article “OPA-3D: Occlusion-Aware Pixel-Wise Aggregation for Monocular 3D Object Detection” was published in the prestigious IEEE Robotics and Automation Letters (RA-L) Journal. The work is a collaboration of DFKI with the TU Munich and Google. The article is openly accessible at: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10021668
Abstract: Monocular 3D object detection has recently made a significant leap forward thanks to the use of pre-trained depth estimators for pseudo-LiDAR recovery. Yet, such two-stage methods typically suffer from overfitting and are incapable of explicitly encapsulating the geometric relation between depth and object bounding box. To overcome this limitation, we instead propose to jointly estimate dense scene depth with depth-bounding box residuals and object bounding boxes, allowing a two-stream detection of 3D objects that harnesses both geometry and context information. Thereby, the geometry stream combines visible depth and depth-bounding box residuals to recover the object bounding box via explicit occlusion-aware optimization. In addition, a bounding box based geometry projection scheme is employed in an effort to enhance distance perception. The second stream, named as the Context Stream, directly regresses 3D object location and size. This novel two-stream representation enables us to enforce cross-stream consistency terms, which aligns the outputs of both streams, and further improves the overall performance. Extensive experiments on the public benchmark demonstrate that OPA-3D outperforms state-of-the-art methods on the main Car category, whilst keeping a real-time inference speed.
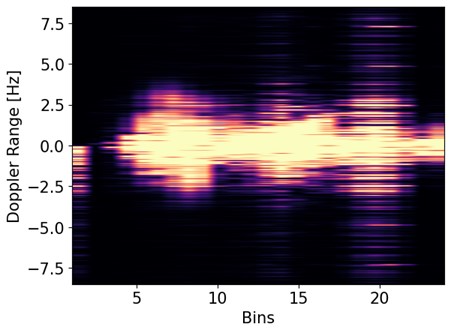
DFKI Augmented Vision recently released the first publicly available UWB Radar Driving Activity Dataset (RaDA), consisting of over 10k data samples from 10 different participants annotated with 6 driving activities. The dataset was recorded in the DFKI driving simulator environment. For more information and to download the dataset please check the project website: https://projects.dfki.uni-kl.de/rada/
The dataset release is accompanied by an article publication at the Sensors journal:
The Augmented Vision department of DFKI participated in the VIZTA project, coordinated by ST Microelectronics, aiming at developing innovative technologies in the field of optical sensors and laser sources for short to long-range 3D-imaging and to demonstrate their value in several key applications including automotive, security, smart buildings, mobile robotics for smart cities, and industry4.0.
The final project review was successfully completed in Grenoble, France on November 17th-18th, 2022. The schedule included presentations on the achievements of all partners as well as live demonstrators of the developed technologies. DFKI presented their smart building person detection demonstrator based on a top-down view from a Time-of-flight (ToF) camera, developed in cooperation with the project partner IEE. A second demonstrator, showing an in-cabin monitoring system based on a wide-field-of-view, which is installed in DFKIs lab has been presented in a video.
During VIZTA, several key results were obtained at DFKI on the topics of in-car and smart building monitoring including:
7 peer reviewed publications in conferences and journals
DFKI Augmented Vision researchers Yongzhi Su, Praveen Nathan and Jason Rambach received their 1st place award in the prestigious BOP Challenge 2022 in the categories Overall Best Segmentation Method and The Best BlenderProc-Trained Segmentation Method.
The BOP benchmark and challenge addresses the problem of 6-degree-of-freedom object pose estimation, which is of great importance for many applications such as robot grasping or augmented reality. This year, the BOP challenge was held within the “Recovering 6D Object Pose” Workshop at the European Conference on Computer Vision (ECCV) in Tel Aviv, Israel https://eccv2022.ecva.net/ . A total award of $4000 was distributed among the winning teams of the BOP challenge, donated by Meta Reality Labs and Niantic.
The awards were received by Dr. Jason Rambach on behalf of the DFKI Team and a short presentation of the method followed. The winning method was based on the CVPR 2022 paper “ZebraPose”
DFKI Augmented Vision had a strong presence in the recent CVPR 2022 Conference held on June 19th-23rd, 2022, in New Orleans, USA. The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) is the premier annual computer vision event internationally. Homepage: https://cvpr2022.thecvf.com/ .
On June 14th, 2022, Dr. Jason Rambach gave a keynote talk in the Computer Vision session of the Franco-German Research and Innovation Network event held at the Inria headquarters in Versailles, Paris, France. In the talk, an overview of the current activities of the Spatial Sensing and Machine Perception team at DFKI Augmented Vision was presented.