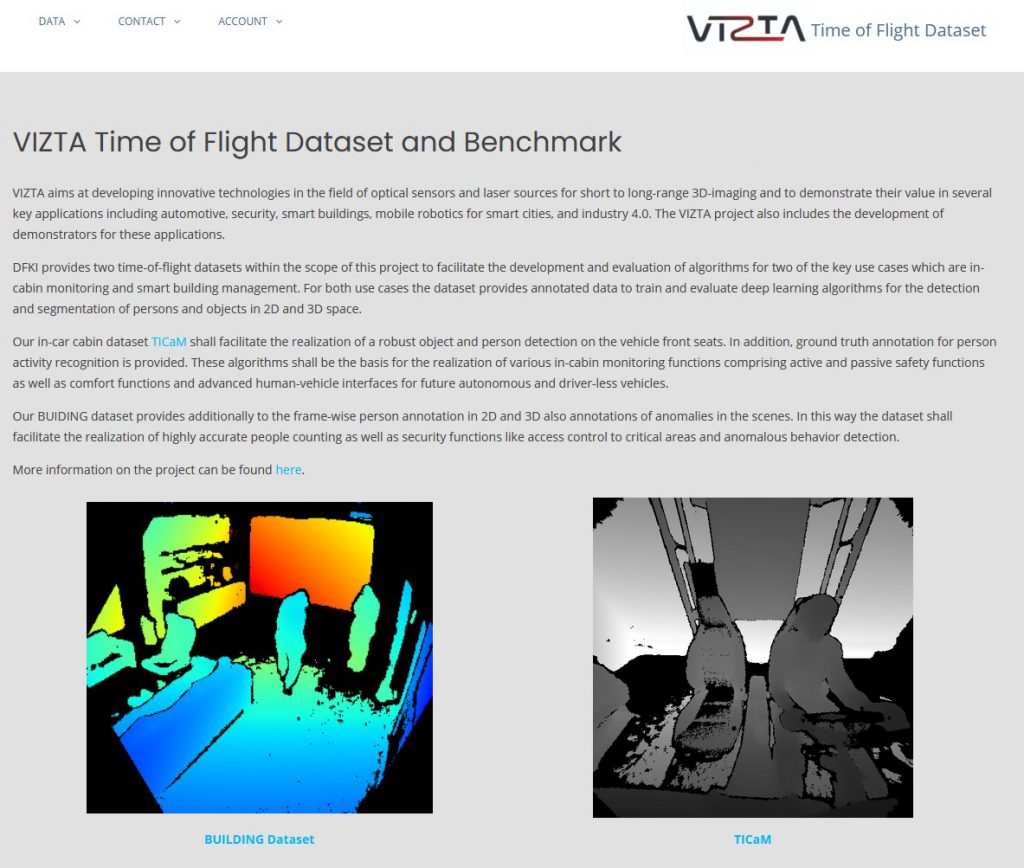
As part of the research activities of DFKI Augmented Vision in the VIZTA project (https://www.vizta-ecsel.eu/), we have published the open-source dataset for automotive in-cabin monitoring with a wide-angle time-of-flight depth sensor. The TiCAM dataset represents a variety of in-car person behavior scenarios and is annotated with 2D/3D bounding boxes, segmentation masks and person activity labels. The dataset is available here https://vizta-tof.kl.dfki.de/. The publication describing the dataset in detail is available as a preprint here: https://arxiv.org/pdf/2103.11719.pdf
Abstract: Instance segmentation of planar regions in indoor scenes benefits visual SLAM and other applications such as augmented reality (AR) where scene understanding is required. Existing methods built upon two-stage frameworks show satisfactory accuracy but are limited by low frame rates. In this work, we propose a real-time deep neural architecture that estimates piece-wise planar regions from a single RGB image. Our model employs a variant of a fast single-stage CNN architecture to segment plane instances. Considering the particularity of the target detected, we propose Fast Feature Non-maximum Suppression (FF-NMS) to reduce the suppression errors resulted from overlapping bounding boxes of planes. We also utilize a Residual Feature Augmentation module in the Feature Pyramid Network (FPN) . Our method achieves significantly higher frame-rates and comparable segmentation accuracy against two-stage methods. We automatically label over 70,000 images as ground truth from the Stanford 2D-3D-Semantics dataset. Moreover, we incorporate our method with a state-of-the-art planar SLAM and validate its benefits.
We are happy to announce that two of our papers have been accepted and published in the IEEE Access journal. IEEE Access is an award-winning, multidisciplinary, all-electronic archival journal, continuously presenting the results of original research or development across all of IEEE’s fields of interest. The articles are published with open access to all readers. The research is part of the BIONIC project and was funded by the European Commission under the Horizon 2020 Programme Grant Agreement n. 826304.
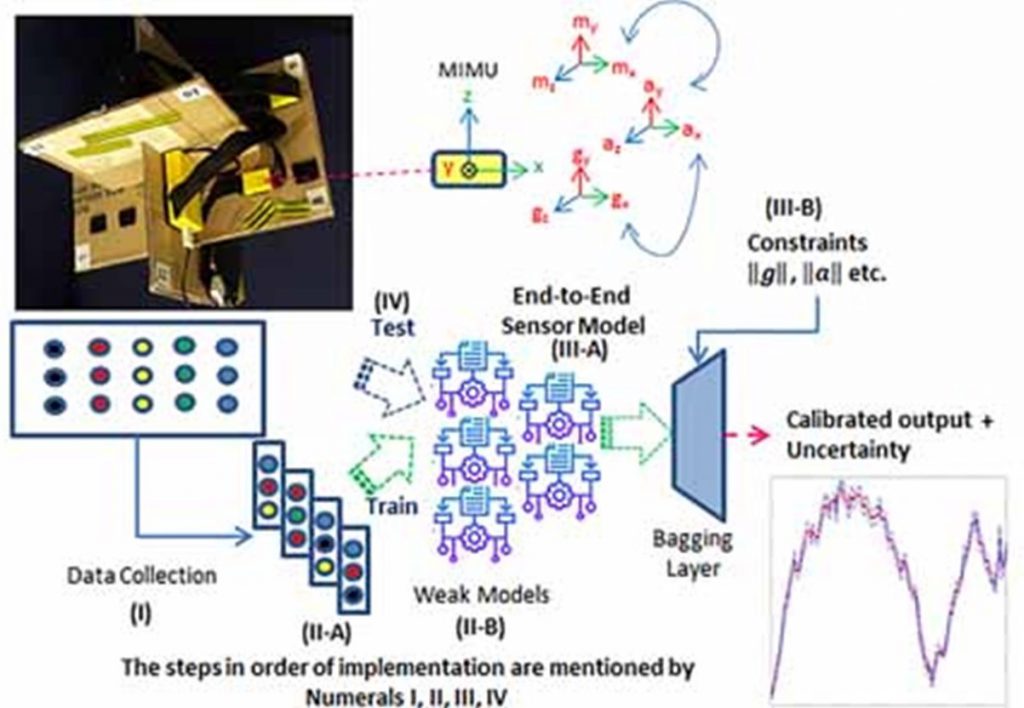
“Simultaneous End User Calibration of Multiple Magnetic Inertial Measurement Units With Associated Uncertainty” Published in: IEEE Access (Volume: 9) Page(s): 26468 – 26483 Date of Publication: 05 February 2021 Electronic ISSN: 2169-3536 DOI: 10.1109/ACCESS.2021.3057579
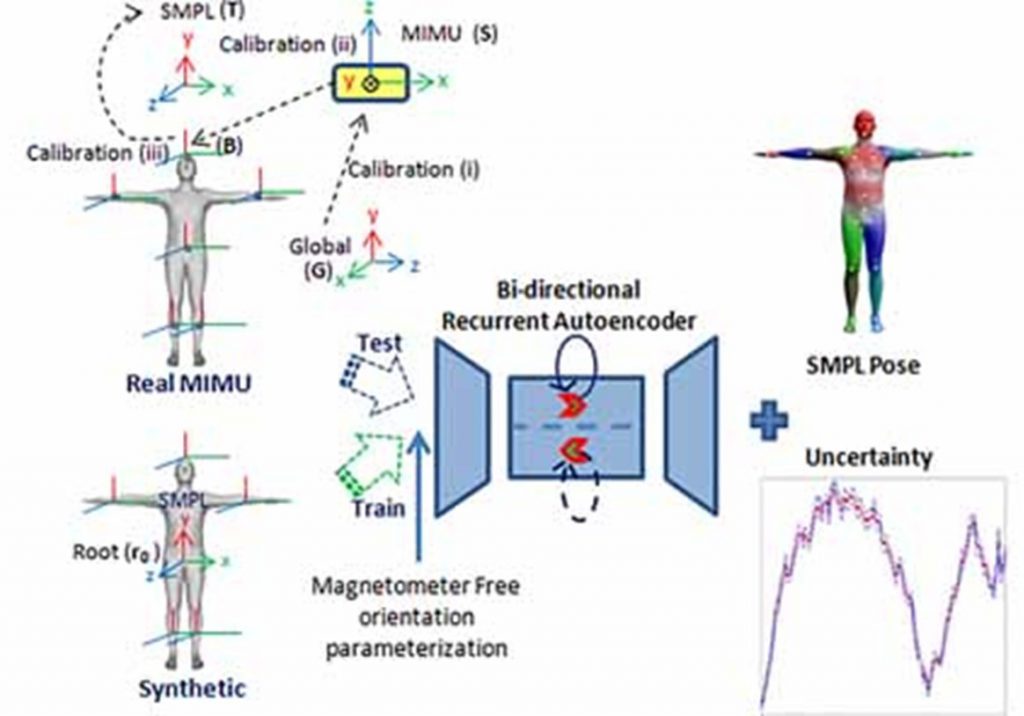
“Magnetometer Robust Deep Human Pose Regression With Uncertainty Prediction Using Sparse Body Worn Magnetic Inertial Measurement Units” Published in: IEEE Access (Volume: 9) Page(s): 36657 – 36673 Date of Publication: 26 February 2021 Electronic ISSN: 2169-3536 DOI: 10.1109/ACCESS.2021.3062545
On March 4th, 2021, Dr. Jason Rambach gave a talk on Machine Learning and Computer Vision at the GIZ (Deutsche Gesellschaft für Internationale Zusammenarbeit) workshop on Machine Learning and Computer Vision for Earth Observation organized by the DFKI MLT department. In the talk, the foundations of Computer Vision, Machine Learning and Deep Learning as well as current Research and Implementation challenges were presented.
Presentation by our senior researcher Dr. Jason RambachAgenda of the GIZ workshop on Machine Learning and Computer Vision for Earth Observation
DFKI participates in the VIZTA project, coordinated by ST Micrelectronics, aiming at developing innovative technologies in the field of optical sensors and laser sources for short to long-range 3D-imaging and to demonstrate their value in several key applications including automotive, security, smart buildings, mobile robotics for smart cities, and industry4.0. The 18-month public summary of the project was released, including updates from DFKI Augmented Vision on time-of-flight camera dataset recording and deep learning algorithm development for car in-cabin monitoring and smart building person counting and anomaly detection applications.
Please click here to check out the complete summary.
We are excited to announce that the Augmented Vision group will present 3 papers in the upcoming VISAPP 2021 Conference, February 8th-10th, 2021:
The International
Conference on Computer Vision Theory and Applications (VISAPP) is part of
VISIGRAPP, the 16th International Joint Conference on Computer Vision, Imaging
and Computer Graphics Theory and Applications. VISAPP aims at becoming a major
point of contact between researchers, engineers and practitioners on the area
of computer vision application systems. Homepage: http://www.visapp.visigrapp.org/
We are happy to announce
that our paper “SynPo-Net–Accurate and Fast
CNN-Based 6DoF Object Pose Estimation Using Synthetic Training” has been
accepted for publication at the MDPI Sensors journal, Special Issue Object
Tracking and Motion Analysis. Sensors (ISSN 1424-8220; CODEN: SENSC9)
is the leading international peer-reviewed open access journal on the science and technology of sensors.
Abstract: Estimation and
tracking of 6DoF poses of objects in images is a challenging problem of great
importance for robotic interaction and augmented reality. Recent approaches
applying deep neural networks for pose estimation have shown encouraging
results. However, most of them rely on training with real images of objects
with severe limitations concerning ground truth pose acquisition, full coverage
of possible poses, and training dataset scaling and generalization capability.
This paper presents a novel approach using a Convolutional Neural Network (CNN)
trained exclusively on single-channel Synthetic images of objects to regress
6DoF object Poses directly (SynPo-Net). The proposed SynPo-Net is a network
architecture specifically designed for pose regression and a proposed domain
adaptation scheme transforming real and synthetic images into an intermediate
domain that is better fit for establishing correspondences. The extensive
evaluation shows that our approach significantly outperforms the
state-of-the-art using synthetic training in terms of both accuracy and speed.
Our system can be used to estimate the 6DoF pose from a single frame, or be
integrated into a tracking system to provide the initial pose.
After two years of collaborative work, the project ArInfuse is inviting for its final workshop on January 28th.
ARinfuse is an Erasmus+ project that aims to infuse skills in Augmented Reality for geospatial information management in the context of utility underground infrastructures, such as water, sewage, electricity, gas and fiber optics. In this field, there is a real need for an accurate positioning of the underground utilities, to avoid damages to the existing infrastructures. Information communication technologies (ICT), in fusion with global navigation satellite systems (GNSS), GIS and geodatabases and augmented/virtual reality (AR/VR) are able to offer the possibility to convert the geospatial information of the underground utilities into a powerful tool for field workers, engineers and managers. ARinfuse is mainly addressed to technical professional profiles (future and current) in the utility sector that use, or are planning to use AR technology into practical applications of ordinary management and maintenance of utility networks.
The workshop entitled “Exploiting the potential of Augmented Reality & Geospatial Technologies within the utilities sector” is addressed to engineering students and professionals that are interested in the function, appliance and benefits of AR and geospatial technologies in the utilities sector.
The workshop will also introduce the ARinfuse catalogue of training modules on Augmented Reality and Geoinformatics applied within the utility infrastructure sector.
We are proud to announce that the Augmented Vision group will present three papers in the upcoming ICPR 2020 conference which will take place from January 10th till 15th, 2021. The International Conference on Pattern Recognition (ICPR) is the premier world conference in Pattern Recognition. It covers both theoretical issues and applications of the discipline. The 25th event in this series is organized as an online virtual conference with more than 1800 participants expected.
The Winter Conference on Applications of Computer Vision (WACV 2021) is IEEE’s and the PAMI-TC’s premier meeting on applications of computer vision. With its high quality and low cost, it provides an exceptional value for students, academics and industry researchers. In 2021, the conference is organized as a virtual online event from January 5th till 9th, 2021.
Abstract: This paper demonstrates a system capable of combining a sparse, indirect, monocular visual SLAM, with both offline and real-time Multi-View Stereo (MVS) reconstruction algorithms. This combination overcomes many obstacles encountered by autonomous vehicles or robots employed in agricultural environments, such as overly repetitive patterns, need for very detailed reconstructions, and abrupt movements caused by uneven roads. Furthermore, the use of a monocular SLAM makes our system much easier to integrate with an existing device, as we do not rely on a LiDAR (which is expensive and power consuming), or stereo camera (whose calibration is sensitive to external perturbation e.g. camera being displaced). To the best of our knowledge, this paper presents the first evaluation results for monocular SLAM, and our work further explores unsupervised depth estimation on this specific application scenario by simulating RGB-D SLAM to tackle the scale ambiguity, and shows our approach produces econstructions that are helpful to various agricultural tasks. Moreover, we highlight that our experiments provide meaningful insight to improve monocular SLAM systems under agricultural settings.
Abstract: Images recorded during the lifetime of computer vision based systems undergo a wide range of illumination and environmental conditions affecting the reliability of previously trained machine learning models. Image normalization is hence a valuable preprocessing component to enhance the models’ robustness. To this end, we introduce a new strategy for the cost function formulation of encoder-decoder networks to average out all the unimportant information in the input images (e.g. environmental features and illumination changes) to focus on the reconstruction of the salient features (e.g. class instances). Our method exploits the availability of identical sceneries under different illumination and environmental conditions for which we formulate a partially impossible reconstruction target: the input image will not convey enough information to reconstruct the target in its entirety. Its applicability is assessed on three publicly available datasets. We combine the triplet loss as a regularizer in the latent space representation and a nearest neighbour search to improve the generalization to unseen illuminations and class instances. The importance of the aforementioned post-processing is highlighted on an automotive application. To this end, we release a synthetic dataset of sceneries from three different passenger compartments where each scenery is rendered under ten different illumination and environmental conditions: https://sviro.kl.dfki.de
Jameel Malik successfully defended his PhD thesis entitled “Deep Learning-based 3D Hand Pose and Shape Estimation from a Single Depth Image: Methods, Datasets and Application” in the presence of the PhD committee made up of Prof. Dr. Didier Stricker (Technische Universitat Kaiserslautern), Prof. Dr. Karsten Berns (Technische Universitat Kaiserslautern), Prof. Dr. Antonis Argyros (University of Crete) and Prof. Dr. Sebastian Michel (Technische Universitat Kaiserslautern) on Wednesday, November 11th, 2020.
In his thesis, Jameel Malik addressed the unique challenges of 3D hand pose and shape estimation, and proposed several deep learning based methods that achieve the state-of-the-art accuracy on public benchmarks. His work focuses on developing an effective interlink between the hand pose
and shape using deep neural networks. This interlink allows to improve the
accuracy of both estimates. His recent paper on 3D convolution based hand pose and shape estimation network was accepted at the premier
conference IEEE/CVF CVPR 2020.
Jameel Malik recieved his bachelors and master degrees in electrical engineering from University of Engineering and Technology (UET) and National University of Sciences and Technology (NUST) Pakistan, respectively. Since 2017, he has been working at the Augmented Vision (AV) group DFKI as a researcher. His research interests include computer vision and deep learning.
Mr. Malik right after his successful PhD defense.
A week later, on Thurday, November 19th, 2020, Mr. Markus Miezal also successfully defended his PhD thesis entitled “Models, methods and error source investigation for real-time Kalman filter based inertial human body tracking” in front of the PhD committee consisting of Prof. Dr. Didier Stricker (TU Kaiserslautern and DFKI), Prof. Dr. Björn Eskofier (FAU Erlangen) and Prof. Dr. Karsten Berns (TU Kaiserslautern).
The goal of the thesis is to work towards a robust human body tracking system based on inertial sensors. In particular the identification and impact of different error sources on tracking quality are investigated. Finally, the thesis proposes a real-time,
magnetometer-free approach for tracking the lower body with ground contact and
translation information. Among the first author publications of the
contributions, one can find a journal article in MDPI Sensors and a conference
paper on the ICRA 2017.
In 2010, Markus Miezal received his diploma in computer science from the University of Bremen, Germany and started working at the Augmented Vision group at DFKI on visual-inertial sensor fusion and body tracking. In 2015, he followed Dr. Gabriele Bleser into the newly founded interdisciplinary research group wearHEALTH at the TU Kaiserslautern, where the research on body tracking continued, focussing on health related applications such as gait analysis. While finishing his PhD thesis, he co-founded the company sci-track GmbH as spin-off from TU KL and DFKI GmbH, which aims to transfer robust inertial human body tracking algorithms as middleware to industry partners. In the future Markus will continue research at university and support the company.
The Project ENNOS integrates color and depth cameras with the capabilities of deep neural networks on a compact FPGA-based platform to create a flexible and powerful optical system with a wide range of applications in production contexts. While FPGAs offer the flexibility to adapt the system to different tasks, they also constrain the size and complexity of the neural networks. The challenge is to transform the large and complex structure of modern neural networks into a small and compact FPGA architecture. To showcase the capabilities of the ENNOS concept three scenarios have been selected. The first scenario covers the automatic anonymization of people during remote diagnosis, the second one addresses semantic 3D scene segmentation for robotic applications and the third one features an assistance system for model identification and stocktaking in large facilities.
During the milestone review a prototype of the ENNOS camera could be presented. It integrates color and depth camera as well as an FPGA for the execution of neural networks in the device. Furthermore, solutions for the three scenarios could be demonstrated successfully with one prototype already running entirely on the ENNOS platform. This demonstrates that the project is on track to achieve its goals and validates the fundamental approach and concept of the project.
Project Partners: Robert Bosch GmbH Deutsches Forschungszentrum für Künstliche Intelligenz GmbH (DFKI) KSB SE & Co. KGaA ioxp GmbH ifm eletronic GmbH* PMD Technologies AG*
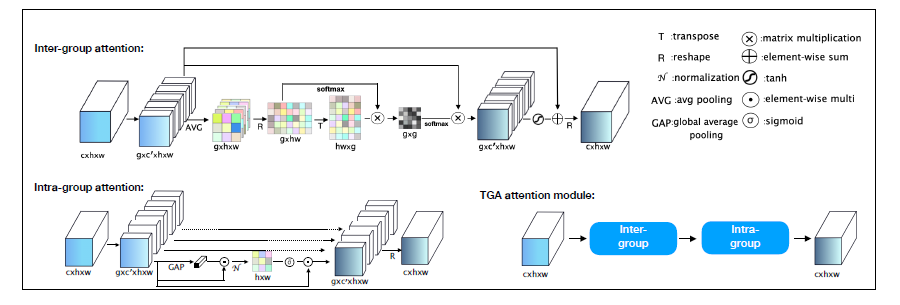
We are happy to announce that our paper “TGA: Two-level Group Attention for Assembly State Detection” has been accepted for publication at the IEEE International Symposium on Mixed and Augmented Reality (ISMAR), which will take place online from November 9th to 13th. The IEEE ISMAR is the leading international academic conference in the fields of Augmented Reality and Mixed Reality. The symposium is organized and supported by the IEEE Computer Society, IEEE VGTC and ACM SIGGRAPH.
Abstract: Assembly state detection, i.e., object state detection, has a critical meaning in computer vision tasks, especially in AR assisted assembly. Unlike other object detection problems, the visual difference between different object states can be subtle. For the better learning of such subtle appearance difference, we proposed a two-level group attention module (TGA), which consists of inter-group attention and intro-group attention. The relationship between feature groups as well as the representation within a feature group is simultaneously enhanced. We embedded the proposed TGA module in a popular object detector and evaluated it on two new datasets related to object state estimation. The result shows that our proposed attention module outperforms the baseline attention module.
PTC has acquired ioxp GmbH, a German industrial start-up for cognitive AR and AI software. ioxp is a spin-off from the Augmented Vision Department of the German Research Center for Artificial Intelligence GmbH (DFKI). For more Information click here or here (both articles in German only).
Congratulations to Dr. Vladislav Golyanik! He received the DAGM MVTec Dissertation Award 2020 for his outstanding dissertation on “Robust Methods for Dense Monocular Non-Rigid 3DReconstruction and Alignment of PointClouds”. For more Information please click here.
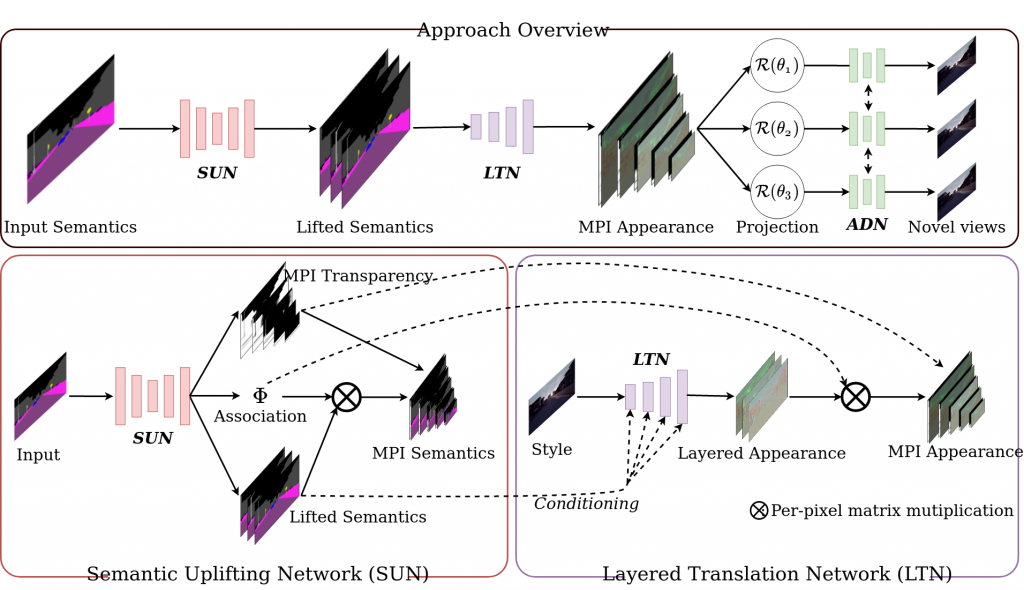
We are happy to announce that our paper “Generative View Synthesis: From Single-view Semantics to Novel-view Images” has been accepted for publication at the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS 2020), which will take place online from December 6th to 12th. NeurIPS is the top conference in the field of Machine Learning. Our paper was accepted from 9454 submissions as one of 1900 (acceptance rate: 20.1%).
Abstract: Content creation, central to applications such as virtual reality, can be a tedious and time-consuming. Recent image synthesis methods simplify this task by offering tools to generate new views from as little as a single input image, or by converting a semantic map into a photorealistic image. We propose to push the envelope further, and introduce Generative View Synthesis (GVS), which can synthesize multiple photorealistic views of a scene given a single semantic map. We show that the sequential application of existing techniques, e.g., semantics-to-image translation followed by monocular view synthesis, fail at capturing the scene’s structure. In contrast, we solve the semantics-to-image translation in concert with the estimation of the 3D layout of the scene, thus producing geometrically consistent novel views that preserve semantic structures. We first lift the input 2D semantic map onto a 3D layered representation of the scene in feature space, thereby preserving the semantic labels of 3D geometric structures. We then project the layered features onto the target views to generate the final novel-view images. We verify the strengths of our method and compare it with several advanced baselines on three different datasets. Our approach also allows for style manipulation and image editing operations, such as the addition or removal of objects, with simple manipulations of the input style images and semantic maps respectively.
On July 10th, 2020, Mr Jason Rambach successfully defended his PhD thesis entitled “Learning Priors for Augmented Reality Tracking and Scene Understanding” in front of the examination commission consisting of Prof. Dr. Didier Stricker (TU Kaiserslautern and DFKI), Prof. Dr. Guillaume Moreau (Ecole Centrale de Nantes) and Prof. Dr. Christoph Grimm (TU Kaiserslautern).
In his thesis, Jason Rambach addressed the combination of geometry-based computer vision techniques with machine learning in order to advance the state-of-the-art in tracking and mapping systems for Augmented Reality. His scientific contributions, in the fields of model-based object tracking and SLAM were published in high-rank international peer-reviewed conferences and journals such as IEEE ISMAR and MDPI Computers. His “Augmented Things” paper, proposing the concept of IoT objects that can store and share their AR information received the best poster paper award at the ISMAR 2017 conference.
Jason Rambach holds a Diploma in Computer Engineering from the University of Patras, Greece and a M.Sc. in Information and Communication Engineering from the TU Darmstadt, Germany. Since 2015, he has been at the Augmented Vision group of DFKI where he was responsible for the BMBF-funded research projects ProWiLan and BeGreifen and several industry projects with leading Automotive Companies in Germany. Jason Rambach will remain at DFKI AV as a Team Leader for the newly formed team “Spatial Sensing and Machine Perception” focused on depth sensing devices and scene understanding using Machine Learning.
Professor Dr. Didier Stricker and Dr. Jason Rambach at the TU Kaiserslautern after his successful PhD defense.
Patientinnen und Patienten erhalten nach Operationen an Blase, Prostata oder Nieren standardmäßig eine kontinuierliche Dauerspülung der Blase, um Komplikationen durch Blutgerinnsel zu vermeiden. Die Spülung sollte ständig überwacht werden, was jedoch im klinischen Alltag nicht zu leisten ist.
Das Ziel von VisIMon ist es, eine bessere Patientenversorgung bei gleichzeitiger Entlastung des Personals durch eine automatisierte Überwachung der Spülung zu erreichen. Im Projekt wird ein kleines, am Körper getragenes Modul entwickelt, welches den Spülvorgang mit unterschiedlichen Sensoren überwacht. Das System soll sich nahtlos in bestehende Abläufe einfügen lassen. Durch den Zusammenschluss interdisziplinärer Partner aus Industrie und Forschung sollen die notwendigen Sensoren und Schnittstellen entwickelt und zu einem effektiven System vereint werden. Dabei soll moderne Kommunikationstechnologie neue Konzepte ermöglichen, bei denen die Komponenten des Systems drahtlos miteinander kommunizieren, über nutzerfreundliche, interaktive Schnittstellen Daten zur Verfügung stellen und sich durch die Nutzer steuern lassen.
Sensoren, Elektronik zur Auswertung sowie die dazugehörige Systemsoftware zur Bestimmung des Hämoglobins sowie zur Messung der Spülgeschwindigkeit und Füllmengenüberwachung wurden nun erfolgreich am DFKI entwickelt und dem Partner DITABIS zur Integration übergeben. Das System verwendet Eingebettete Künstliche Intelligenz bei der Ermittlung der Messwerte und kann so aktiv und robust auf technische Herausforderungen wie Blasenbildung oder mechanische Erschütterungen reagieren.
Abstract We propose a novel architecture with 3D convolutions for simultaneous 3D hand shape and pose estimation trained in a weakly-supervised manner. The input to our architecture is a 3D voxelized depth map. For shape estimation, our architecture produces two different hand shape representations. The first is the 3D voxelized grid of the shape which is accurate but does not preserve the mesh topology and the number of mesh vertices. The second representation is the 3D hand surface which is less accurate but does not suffer from the limitations of the first representation. To combine the advantages of these two representations, we register the hand surface to the voxelized hand shape. In extensive experiments, the proposed approach improves over the state-of-the-art for hand shape estimation on the SynHand5M dataset by 47.8%. Moreover, our 3D data augmentation on voxelized depth maps allows to further improve the accuracy of 3D hand pose estimation on real datasets. Our method produces visually more reasonable and realistic hand shapes of NYU and BigHand2.2M datasets compared to the existing approaches.
We are very happy to announce that three of our PhD students have been able to successfully defend their PhD thesis during 2019!
Mr. Aditya Tewari defended his thesis with the title “Prior-Knowledge Addition to Spatial and Temporal Classification Models with Demonstration on Hand Shape and Gesture Classification” on October 25th in front of the examination commission consisting of Prof. Dr. Didier Stricker (TU Kaiserslautern and DFKI), Prof. Dr. Paul Lukowicz (TU Kaiserslautern and DFKI) and Prof. Dr. Dr. h. c. Dieter Rombach (Fraunhofer IESE, Kaiserslautern).
Mr. Aditya Tewari during his PhD defense on October 25th, 2019
Mr. Vladislav Golyanik defended his thesis with the title „Robust Methods for Dense Monocular Non-Rigid 3D Reconstruction and Alignment of Point Clouds” on November 20th in front of the examination commission consisting of Prof. Dr. Didier Stricker (TU Kaiserslautern and DFKI), Prof. Dr. Antonio Aguado (Universitat Politècnica de Catalunya, Spain) and Prof. Dr. Reinhard Koch (Christian-Albrechts-Universität zu Kiel).
Mr. Vladislav Golyanik during his PhD defense on November 20th, 2019
Mr. Christian Bailer defended his thesis with the title „New Data Based Matching Strategies for Visual Motion Estimation” on November 22nd in front of the examination commission consisting of Prof. Dr. Didier Stricker (TU Kaiserslautern and DFKI), Prof. Dr. Michael Feslberg (Linköpings University, Sweden) and Dr. Margret Keuper (Max-Planck-Institut für Informatik, Saarbrücken).
Mr. Christian Bailer during his PhD defense on November 22nd, 2019
All three PhDs have left our Augmented Vision Department shortly after their defense to pursue a career outside of DFKI.