SPADE stands for Secure, Privacy-Aware Naturalistic Driving Data for Future Mobility Insights from Structured and Unstructured Environments. The workshop had a full-day schedule consisting of invited talks and submitted papers, all with thematic relation to the BERTHA EU Horizon Project.
The Augmented Vision department had a strong presence at the IEEE Computer Vision and Pattern Recognition CVPR 2025 conference with contributions to the main conference, workshops, and challenges:
Dr. Jason Rambach, was honored as an Outstanding Reviewer of the CVPR 2025 conference, selected among the top 5% of the 9872 total reviewers.
The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) is the premier annual computer vision event. CVPR 2025 will be held in Nashville, TN, from June 11th to June 15th 2025.
The complete list of outstanding reviewers for this year can be accessed HERE.
René Schuster gave a talk on “Visual Continual Learning – Beyond Current Incremental Settings” during the 2nd Workshop on Human-Centered Vision and Media Technologies (HCVM) on 23.05.2025 in Tokyo. The workshop was part of the ASPIRE program (Adopting Sustainable Partnerships for Innovative Research Ecosystem) of the Japanese Science and Technology Agency.
On April 11th, 2025 Tewodros Amberbir Habtegebrial successfully defended his doctoral thesis entitled “Learning View Synthesis from Minimal Scene Specifications”.
The PhD thesis was carried out in the Augmented Vision department at DFKI, supervised by Prof. Dr. Didier Stricker.
The PhD examination commission consisted of Prof. Dr. Didier Stricker (RPTU), Prof. Yiorgos Chrysanthou, and was chaired by Prof. Grimm (RPTU).
A great big congratulations on receiving your PhD and we wish you all the best for the future!
On February 24th, 2025 Pramod Murthy successfully defended his doctoral thesis entitled “Monocular Visual Human Pose Parameter Estimation under Partial Observations”.
The PhD thesis was carried out in the Augmented Vision department at DFKI, supervised by Prof. Dr. Didier Stricker.
The PhD examination commission consisted of Prof. Dr. Didier Stricker (RPTU), Prof. Karsten Berns and was chaired by Prof. Nicolas Gauger.
A great big congratulations on receiving your PhD and we wish you all the best for the future!
On May 9th, 2025 Lukas Stäcker successfully defended his doctoral thesis entitled “Radar-Camera Fusion with Deep Neural Networks for Automotive Object Detection”. The PhD thesis was carried out in the Augmented Vision department at DFKI, supervised by Prof. Dr. Didier Stricker and Dr. Jason Rambach, in collaboration with Stellantis.
The PhD examination commission consisted of Prof. Dr. Didier Stricker (RPTU), and Prof. Christoph Stiller (KIT)) and was chaired by Prof. Nicolas Gauger (RPTU).
A great big congratulations on receiving your PhD and we wish you all the best for the future!
Our paper “Spatio-Temporal Diffusion Model for Satellite Imagery” received the Best Paper Award at the Eleventh International Conference on Remote Sensing and Geoinformation of Environment (RSCy 2025).
Starting from sparse satellite observations, our method predicts how landscapes might evolve in the future with changes such as urban expansions or deforested regions, by leveraging a Diffusion Transformer with temporal layers. By training on open-source Landsat and Sentinel-2 data, the model generates future scenarios from a single reference image and a specified target year. This approach provides powerful insights into environmental changes, supporting both climate impact assessments and resource management.
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) provides a forum for computer vision researchers working on practical applications and innovative algorithms to share their latest developments. WACV 2025 was held in Tucson, Arizona, from February 28th to March 4th.
The researchers of the Augmented Vision department have presented 4 papers at the ICPRAM 2025 conference taking place Feb 23 – 25, 2025 in Porto, Portugal.
The International Conference on Pattern Recognition Applications and Methods (ICPRAM) is a point of contact between researchers and engineers working on Pattern Recognition, both from a theoretical and application perspective.
The researchers of the department Augmented Vision have presented 4 papers at WACV 2025 conference taking place Feb 28 – Mar 4, 2025 in Tucson, Arizona, USA.
The IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) one of the three major Computer Vision conferences organized by TCPAMI.
“AnonyNoise: Anonymizing Event Data with Smart Noise to Outsmart Re-Identification and Preserve Privacy”, Katharina Bendig, René Schuster, Nicole Thiemer, Karen Joisten, Didier Stricker
The consortium of the HumanTech project, under the coordination of DFKI Augmented Vision – Dr. Jason Rambach, had its final in-person General Assembly meeting in Madrid, Spain on the 30-31st January 2025. The meeting was hosted in the premises of the project partner ACCIONA. All project partners had an opportunity to experience live demonstrations of the HumanTech technologies bringing AI and Robots to construction sites, such as intention-activated exoskeletons for construction workers and collaborative brick-laying robots.
The HumanTech project is ending in May 2025 with several success stories such as:
5 innovative pilot deployments of HumanTech technologies.
15+ scientific publications including top computer vision and robotics journals and conferences.
5 awards for DFKI in International challenges in object pose estimation and Scan-to-BIM.
Building a vibrant community for AI in Construction, the Tech4Construction cluster.
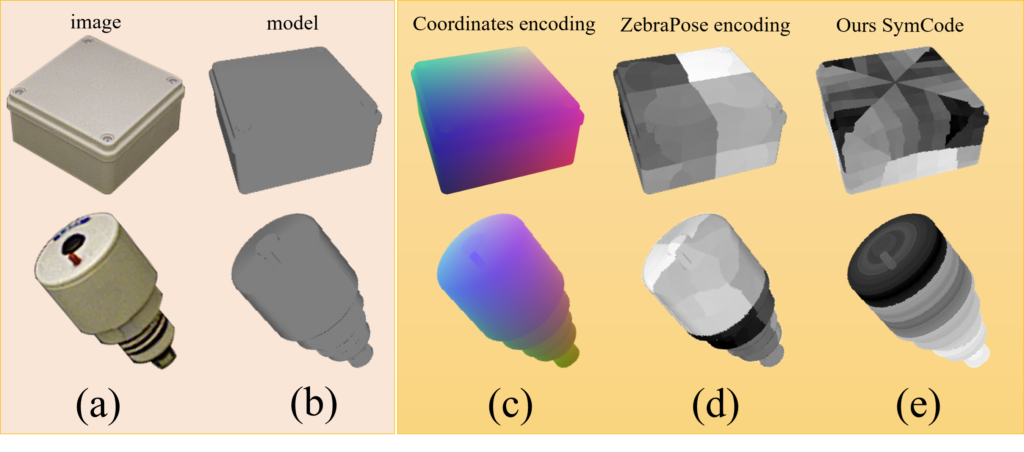
Our article “Resolving Symmetry Ambiguity in Correspondence-based Methods for Instance-level Object Pose Estimation” was published in the prestigious Transactions on Image Processing (TIP) Journal. The work is a collaboration of DFKI with Zhejiang University. The article is openly accessible at: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10906413
Yongliang Lin, Yongzhi Su, Sandeep Inuganti, Yan Di, Naeem Ajilforoushan, Hanqing Yang, Yu Zhang, Jason Rambach. “Resolving Symmetry Ambiguity in Correspondence-based Methods for Instance-level Object Pose Estimation” IEEE Transaction on Image Processing (2025).
Three EU projects coordinated by the AV department have been presented in a meeting of the Virtual and Augmented Reality Industrial Coalition, hosted by the European Commission in Brussels on February 11th and 12th 2025. The meeting brought together over 110 attendees from more than 80 private and public organisations for discussions about the creation of a Private Public Partnership on Virtual Worlds.
The Augmented Vision department presented its work on extended reality (XR) in the projects CORTEX² (Coordinator: Alain Pagani), LUMINOUS (Coordinator: Zeshan Afzal) and SHARESPACE (Coordinator: Didier Stricker), and participated intensively to the discussions about the Strategic Research and Innovation Agenda (SRIA) of the future Virtual Worlds Partnership.
The topics covered immersion & visualization, intuitive real-time user interaction, standardisation & interoperability, digital twins and XR use cases such as logistics & industry, healthcare, culture media & arts or education.
The department Augmented Vision will continue to represent DFKI in the future partnership on Virtual Worlds with eXtended Reality as key enabling technology.
More information: https://digital-strategy.ec.europa.eu/en/news/virtual-and-augmented-reality-industrial-coalition-remains-committed-solving-real-world-problems
On December 19th, 2024, Jilliam Díaz Barros successfully defended her doctoral thesis entitled ‘Optimization and Generative Models for Face Analysis’. The PhD thesis was carried out in the Augmented Vision department at DFKI, led by Prof. Dr. Didier Stricker, as part of the Computer Science department at RPTU.
The PhD examination commission consisted of Prof. Dr. Didier Stricker (RPTU) and Prof. Dr. Luís Gonzaga Mendes Magalhães (University of Minho) and was chaired by Prof. Dr. Annette Bieniusa (RPTU).
In her thesis, Jilliam Díaz investigated the modelling of the rigid and non-rigid motions of the head, targeting existing challenges in assistance tools and assistive technologies. The PhD thesis focused on four main areas of contributions: head pose estimation, performance-driven facial animation, facial landmark detection and tracking, and face and upper body image synthesis.
Jilliam Díaz received her Bachelor degree in Electronics Engineering from Universidad del Norte, Colombia and her M.Sc. in Computer Science and Electronics from the Université de Bourgogne, France. Besides being part of the Augmented Vision department, Ms. Díaz Barros has been working as software engineer at ANNA Healthcare Saarland UG.
A great big congratulations on receiving your PhD and we wish you all the best for the future!
The workshop “Excellence in AI and Edge Computing” held on Monday, 20 January, was dedicated to exploring the frontiers of the AI and edge computing synergy, focusing on the development of scalable and robust AI systems. It opened with a keynote by Dr. Alireza Dehghani from the Irish National Centre for Applied AI CeADAR, followed by the presentation of 15 scientific papers and a demo session. The workshop closed with a matchmaking session about “Industrial investment priorities for successful AI at the Edge in Europe”.
The workshop “Charting the Future of Edge AI: Functional and Non-Functional Requirements in the Age of Generative AI” held on Tuesday, 21 January, was organized by Ovidiu Vermesan (SINTEF) and Alain Pagani (DFKI). It provided a comprehensive platform for stakeholders to exchange ideas, share experiences, and collaborate on advancing edge AI technologies, with a special focus on addressing functional and non-functional requirements defined based on system engineering principles. The three sessions covered “Requirements in the Generative AI Era”, “Technology developments” and “Application developments” with presentations, followed by a panel discussion on Edge AI Future Trends.
Our paper “G3FA: Geometry-guided GAN for Face Animation” was presented at the British Machine Vision Conference (BMVC) 2024 by Alireza Javanmardi from the Augmented Vision Department DFKI!
The British Machine Vision Conference (BMVC) is one of the major international conferences on computer vision and related areas and is organised by the British Machine Vision Association (BMVA). This year it was held in Glasgow from November 25th to 28th.
Our work presents a method for real-time face re-enactment from one single source image and addresses a key limitation of GAN-based face animation: geometric consistency.
G3FA enhances realism, especially in challenging head poses, by:
Utilizing implicit 3D supervision through inverse rendering to extract depth and normal maps from 2D images, guiding the generator towards greater accuracy.
Employing an ensemble of discriminators to incorporate the 3D properties, improving the generator’s understanding of human head structure.
Leveraging face volume rendering with orthogonal ray sampling and volume rendering for high-quality image synthesis.
Over the three days, more than 50 presenters took part in 12 keynotes and parallel sessions, addressing more than 20 topics, where participants discussed how Edge AI is redefining the future of technological applications and systems.
dAIEDGE Partners contributed to the EEAI programme with presentations that offered a practical and innovative view of Edge AI in action, highlighting its transformative potential in sectors such as sustainability, energy and security:
FPGA Acceleration for SAR Imagery-Based Sea Ice Mapping: This presentation, by Rashed Al Koutayni (DFKI), addressed the use of FPGA accelerators to improve the speed and accuracy of sea ice mapping using synthetic aperture radar (SAR) imagery.
Functional and Non-Functional Requirements in Edge AI Systems: Ovidiu Vermesan (SINTEF, Norway) and Alain Pagani (DFKI, Germany) discussed the challenges associated with functional and non-functional requirements in Edge AI systems, addressing both operational needs and ethical and legal constraints.
Legal Requirements for Trustworthy Edge AI: Lydia Belkadi from KU Leuven addressed the regulations needed to ensure trustworthy edge AI solutions
The event allowed participants not only to learn from leading experts, but also to network and connect with the best in the industry, strengthening a community of experts and practitioners who are driving innovation in Edge AI.
The researchers of the Augmented Vision department presented their latest research activities in the field of eXtended Reality at the EuroXR conference in Athens, from November 27th to 29th, 2024.
The European Association for eXtended Reality (EuroXR) Conference is the ultimate gathering for Virtual Reality (VR), Augmented Reality (AR), and Mixed Reality (MR). This year, the conference was co-organized by the Institute of Communication and Computer System (ICCS) of the National Technical University of Athens (NTUA).
This year, a joint event on Next Generation XR was co-organized by six European Projects, among them CORTEX2, LUMINOUS and SHARESPACE, all coordinated by the Augmented Vision department at DFKI.
Alain Pagani presented the recent work on cooperative telepresence in the project CORTEX2
Zeshan Afzal featured the use of language models for XR in the project LUMINOUS
The coordinators took part in a panel discussion about the “Future of XR”, in which they could share their view about the next steps in XR research and development.
In addition, the AV group presented two application papers and one demonstrator, which attracted the interest of the conference participants
Dr. Jason Rambach, gave a talk on “Building Virtual Worlds with 3D Sensing and AI” at the NEM Summit 2024 in Brussels on the 23.10.2024. The presentation was part of the AI for Virtual Worlds session organized by Future Artificial Intelligence Research (FAIR). The presentation with results from the Project HumanTech and various XR projects based on object pose estimation technology from DFKI, was followed by an exciting panel discussion.





























{kind=link}