We are proud to have received a Best Paper Award at this year’s ICPR. Please take a look at this article for more information: Machine Learning with Synthetic Data – Research Unit Augmented Vision receives Best Paper Award at ICPR 2022 (dfki.de)
News
We are pleased to announce that the Augmented Vision group presented two papers at the HCI International 2022 Conference from June 28th to July 1st, 2022.

The two accepted papers are:
Title: Learning Effect of Lay people in Gesture-Based Locomotion in Virtual Reality
Authors: Alexander Schäfer, Gerd Reis, Didier Stricker
Abstract: Locomotion in Virtual Reality (VR) is an important part of VR applications. Many scientists are enriching the community with different variations that enable locomotion in VR. Some of the most promising methods are gesture-based and do not require additional handheld hardware. Recent work focused mostly on user preference and performance of the different locomotion techniques. This ignores the learning effect that users go through while new methods are being explored. In this work, it is investigated whether and how quickly users can adapt to a hand gesture-based locomotion system in VR. Four different locomotion techniques are implemented and tested by participants. The goal of this paper is twofold: First, it aims to encourage researchers to consider the learning effect in their studies. Second, this study aims to provide insight into the learning effect of users in gesture-based systems.

Title: Human intelligent machine teaming in single pilot operation: A case study
Authors: Nareg Minaskan Karabid, Charles-Alban Dormoy, Alain Pagani, Jean-Marc Andre, Didier Stricker
Abstract: With recent advances in artificial intelligence (AI) and learning based systems, industries have started to integrate AI components into their products and workflows. In areas where frequent testing and development is possible these systems have proved to be quite useful such as in automotive industry where vehicle are now equipped with advanced driver-assistant systems (ADAS) capable of self-driving, route planning, and maintaining safe distances from lanes and other vehicles. However, as the safety-critical aspect of task increases, more difficult and expensive it is to develop and test AI-based solutions. Such is the case in aviation and therefore, development must happen over longer periods of time and in a step-by-step manner. This paper focuses on creating an interface between the human pilot and a potential assistant system that helps the pilot navigate through a complex flight scenario. Verbal communication and augmented reality (AR) were chosen as means of communication and the verbal communication was carried out in a wizard-of-Oz (WoOz) fashion. The interface was tested in a flight simulator and its usefulness was evaluated by NASA-TLX and SART questionnaires for workload and situation awareness.
Please check out the article “Artificial intelligence for a safe and sustainable construction industry (dfki.de)” concerning the new EU project HumanTech which is coordinated by Dr. Jason Rambach, head of the Spatial Sensing and Machine Perception team (Augmented Reality/Augmented Vision department, Prof. Didier Stricker) at the German Research Center for Artificial Intelligence (DFKI) in Kaiserslautern.
We are happy to announce that our paper titled
Deep Orientation-Guided Gender Recognition from Face Images
Mohamed Selim, Stephan Krauß, Tewodros Amberbir Habtegebrial, Alain Pagani, Didier Stricker
has been accepted and presented (online) at the 12th International Conference on Pattern Recognition Systems, ICPRS-2022.
In this paper, we present a novel deep learning-based method to predict gender using both the face image and the head orientation angles. We show that the use of head orientation information consistently boosts the accuracy of gender prediction models. We achieve this by increasing the representational power of deep neural networks by introducing a head orientation adapter.


The INFINITY consortium had a successful technical meeting in preparation of the upcoming pilot in Sheffield, UK on July 5th, 2022.
The EU project INFINITY aim at delivering an integrated solution for data-driven criminal investigations, synthesising the latest innovations in virtual and augmented reality, artificial intelligence and machine learning with big data and visual analytics. The result of the project will be a platform for collaborative work between Law Enforcement Agencies, where teamwork will be facilitated in virtual spaces and supported by AI-based data analytics.
DFKI is partnering with 19 partners to deliver an innovative solution. DFKI is working on virtual representations and avatars systems, and on an AI-based assistant to help investigation work.
More information: https://h2020-infinity.eu/
Contact: Dr. Alain Pagani
DFKI Augmented Vision had a strong presence in the recent CVPR 2022 Conference held on June 19th-23rd, 2022, in New Orleans, USA. The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) is the premier annual computer vision event internationally. Homepage: https://cvpr2022.thecvf.com/ .
Overall, three publications were presented:
1. ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Yongzhi Su, Mahdi Saleh, Torben Fetzer, Jason Raphael Rambach, Nassir Navab, Benjamin Busam, Didier Stricker, Federico Tombari
2. SOMSI: Spherical Novel View Synthesis with Soft Occlusion Multi-Sphere Images Tewodros A Habtegebrial, Christiano Gava, Marcel Rogge, Didier Stricker, Varun Jampani
3. Unsupervised Anomaly Detection from Time-of-Flight Depth Images
Pascal Schneider, Jason Rambach, Bruno Mirbach , Didier Stricker


On June 14th, 2022, Dr. Jason Rambach gave a keynote talk in the Computer Vision session of the Franco-German Research and Innovation Network event held at the Inria headquarters in Versailles, Paris, France. In the talk, an overview of the current activities of the Spatial Sensing and Machine Perception team at DFKI Augmented Vision was presented.

The project MOVEON has been presented by Dr. Alain Pagani (DFKI) and Romain Boisseau (INRIA) at the 6th edition of the Viva Technology fair in Paris on June 17th, 2022.

Viva Technology, or VivaTech, is an annual technology conference, dedicated to innovation and startups, held in Paris, France. This year, France and Germany have been showcasing their future European digital champions on a single stand: the French-German Tech Lab. This Lab, organized by twelve French and German partners, highlights the most promising startups in their ecosystems, as well as the concrete academic and economic cooperation between the two countries.
MOVEON is a common project between DFKI and INRIA, and is aiming to develop a new generation of visual positioning algorithms that will enable geometric reasoning to be carried out on high-level primitives taken from learning.
More information: https://www.dfki.de/web/forschung/projekte-publikationen/projekte-uebersicht/projekt/moveon
Contact: Dr. Alain Pagani

The EU project INFINITY has concluded its first in-person project meeting in Vienna on April 13th, 2022. This meeting was the occasion for the end user partners to try out the updated VR demos.
INFINITY aims at delivering an integrated solution for data-driven criminal investigations, synthesising the latest innovations in virtual and augmented reality, artificial intelligence and machine learning with big data and visual analytics. The result of the project will be a platform for collaborative work between Law Enforcement Agencies, where teamwork will be facilitated in virtual spaces and supported by AI-based data analytics.
More information: https://h2020-infinity.eu/
Contact: Dr. Alain Pagani
Artificial intelligence (AI) is serving an increasingly significant role in many workplaces — one that continues to grow as new developments in AI and surrounding technologies become available. This leads us to think about how such technologies can be and should be used to empower humans. In this article, Tomokazu Murakami from the Research & Development Group of Hitachi, Ltd. sat down with Didier Stricker, Head of the Augmented Reality Research Department at the German Research Center for Artificial Intelligence (DFKI) to discuss the use of AI in the workplace, its benefits and challenges, human-AI collaboration and its impact on workers.
Check out the full interview “Insights from AI/Analytics: Human-AI collaboration in the industrial sector: what does the future hold?”.

On March 18th, 2022, René Schuster successfully defended his dissertation entitled “Data-driven and Sparse-to-Dense Concepts in Scene Flow Estimation for Automotive Applications”. The reviewers were Prof. Dr. Didier Stricker (Technical University of Kaiserslautern) and Prof. Dr. Andrés Bruhn (University of Stuttgart). Mr. Schuster received his doctorate from the Department of Computer Science at the Technical University of Kaiserslautern.
In his thesis, Mr. Schuster worked on three-dimensional motion estimation of the dynamic environment of vehicles. The focus was on machine learning methods, and the interpolation of individual estimates into a dense motion field. A particular challenge was the scarcity of annotated data for this problem and use case.
René Schuster received an M. Sc. in computational engineering from Darmstadt University of Technology in 2017. He then moved to DFKI to join the augmented reality group of Prof. Stricker. Much of his research was done in collaborative projects with BMW.


On March 18th, 2022, we had the great privilege to demonstrate the BIONIC system to the German chancelor Olaf Scholz during his visit to DFKI GmbH in Kaiserslautern. Dr. Markus Miezal was wearing the BIONIC system on a workstation and presented the real-time ergonomic assessment.
The system consists of work pants and a shirt, which carry inertial measurement units similar to those in a smartphone. Using sensor fusion methods, the body posture of the worker can be extracted to monitor the health of the worker and allows to give feedback, either direct, if the working posture is hazardous or via statistics gathered throughout a workday. Since privacy is a main topic of this project, the data is processed on a small wearable device, similar to a smartphone, so that the personal data literally stays on the person in the first place. Under premise of the workers approval, the data might be shared with his doctor, so that he can make recommendations on exercises according to this phyiscal stress during work. In a further step, the worker might even donate anonymized data to his employer, which allows him to analyze the general ergonomy of the workstation itself.
The chancellor was interested on how long and when to wear the system. Indeed, the system is not meant for every-day use but can be beneficial during training on a new workstation, where new work processes are learnt in an ergonomically sound way. Meanwhile the project has finished, however, spin-offs, e.g. the sci-track GmbH, will continue to provide the technology to the market.
For more information, please check out the following links:
DFKI – BIONIC Video on YouTube (3 minutes, 8 seconds)
DFKI + TUK – Tech Demonstrator (1 minute, 47 seconds)
DFKI Press Release: BUNDESKANZLER OLAF SCHOLZ BESUCHT DAS DFKI


We are happy to announce that the Augmented Vision group will present two papers in the upcoming CVPR 2022 Conference from June 19th-23rd in New Orleans, USA. The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) is the premier annual computer vision event internationally. Homepage: https://cvpr2022.thecvf.com/
The two accepted papers are:
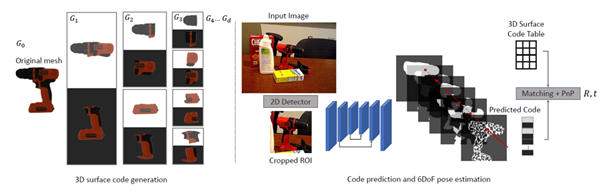
- ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Yongzhi Su, Mahdi Saleh, Torben Fetzer, Jason Raphael Rambach, Nassir Navab, Benjamin Busam, Didier Stricker, Federico Tombari
Summary: ZebraPose sets a new paradigm on model-based 6DoF object pose estimation by using a binary object surface encoding to train a neural network to predict the locations of model vertices in a coarse to fine manner. ZebraPose shows a major improvement over the state-of-the-art on several datasets of the BOP Object Pose Estimation benchmark.
Contact: Yongzhi Su, Dr. Jason Rambach
- SOMSI: Spherical Novel View Synthesis with Soft Occlusion Multi-Sphere Images
Tewodros A Habtegebrial, Christiano Gava, Marcel Rogge, Didier Stricker, Varun Jampani
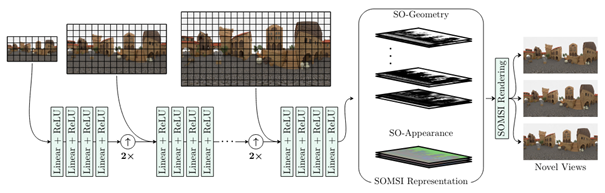
Summary: We propose a novel Multi-Sphere Image representation called Soft Occlusion MSI (SOMSI) and efficient rendering technique that produces accurate spherical novel-views from a sparse spherical light-field. SOMSI models appearance features in a smaller set (e.g. 3) of occlusion levels instead of larger number (e.g. 64) of MSI spheres. Experiments on both synthetic and real-world spherical light-fields demonstrate that using SOMSI can provide a good balance between accuracy and run-time. SOMSI view synthesis quality is on-par with state-of-the-art models like NeRF, while being 2 orders of magnitude faster.
For more information, please visit the project page at https://tedyhabtegebrial.github.io/somsi
Contact: Tewodros A Habtegebrial
We are happy to announce that our project DECODE has been accepted for the Nvidia Academic Hardware Grant. Nvidia will support our research in the field of human motion estimation and semantic reconstruction by donating a Nvidia A100 GPU for data centers. We will use the new hardware to accelerate our experiments for continual learning.
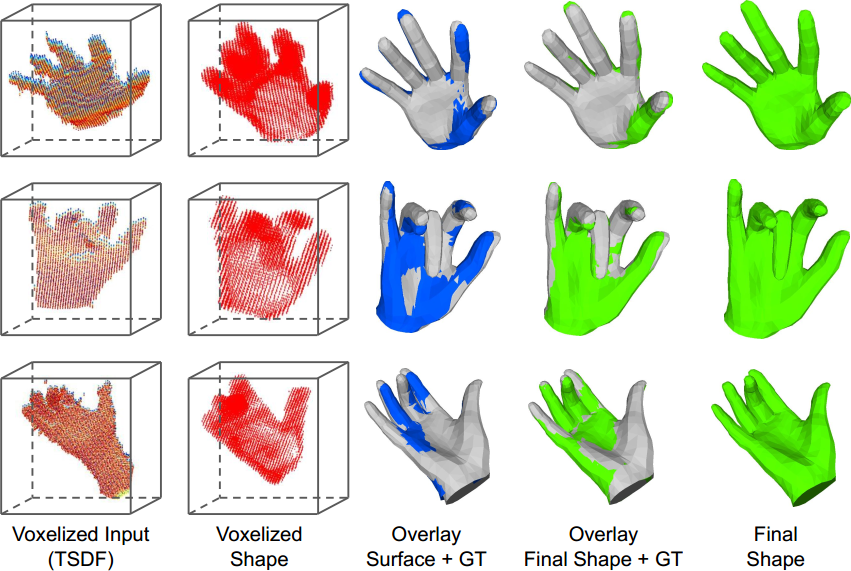
We are very happy to announce that our paper “HandVoxNet++: 3D Hand Shape and Pose Estimation using Voxel-Based Neural Networks” has been accepted for publication in the renowned journal “IEEE Transactions on Pattern Analysis and Machine Intelligence“.
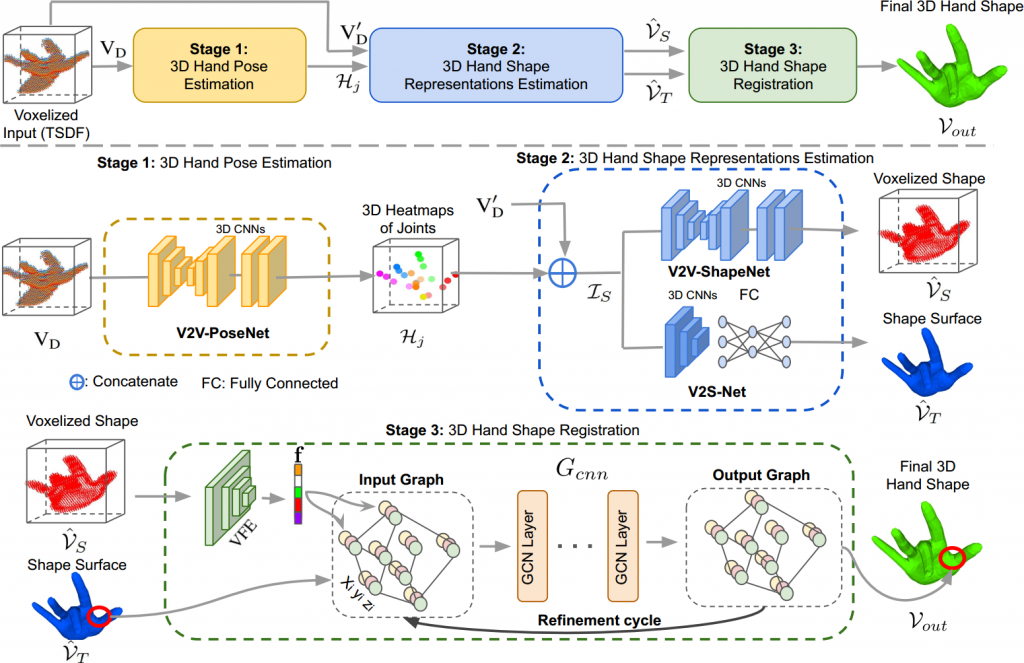
We introduce a new HandVoxNet++ method for 3D hand shape and pose reconstruction from a single depth map, which establishes an effective inter-link between hand pose and shape estimations using 3D and graph convolutions. The input to our network (i.e., HandVoxNet++) is a 3D voxelized depth map based on the truncated signed distance function (TSDF), and it relies two hand shape representations. The first one is the 3D voxelized grid of hand shape, which does not preserve the mesh topology and which is the most accurate representation. The second representation is the hand surface that preserves the mesh topology. We combine the advantages of both representations by aligning the hand surface to the voxelized hand shape either with a new neural Graph-Convolutions-based Mesh Registration (GCN-MeshReg) or classical segment-wise Non-Rigid Gravitational Approach (NRGA++) which does not rely on training data. In this journal extension of our previous approach presented at CVPR 2020, we gain 41.09% and 13.7% higher shape alignment accuracy on SynHand5M and HANDS19 datasets, respectively. Our results indicate that the one-to-one mapping between voxelized depth map, voxelized shape and 3D heatmaps of joints is essential for an accurate hand shape and pose recovery.
We are happy to announce that the Augmented Vision group will present 2 papers in the upcoming BMVC 2021 Conference, 22-25 November, 2021:
The British Machine Vision Conference (BMVC) is the British Machine Vision Association (BMVA) annual conference on machine vision, image processing, and pattern recognition. It is one of the major international conferences on computer vision and related areas held in the UK. With increasing popularity and quality, it has established itself as a prestigious event on the vision calendar. Homepage: https://www.bmvc2021.com/
The 2 accepted papers are:
1. TICaM: A Time-of-flight In-car Cabin Monitoring Dataset
Authors: Jigyasa Singh Katrolia, Ahmed Elsherif, Hartmut Feld, Bruno Mirbach, Jason Raphael Rambach, Didier Stricker
Summary: TICaM is a Time-of-flight In-car Cabin Monitoring dataset for vehicle interior monitoring using a single wide-angle depth camera. The dataset goes beyond currently available in-car cabin datasets in terms of the ambit of labeled classes, recorded scenarios and annotations provided; all at the same time. The dataset is available here: https://vizta-tof.kl.dfki.de/
Video: https://www.youtube.com/watch?v=aqYUY2JzqHU
Contact: Jason Rambach
2. PlaneRecNet: Multi-Task Learning with Cross-Task Consistency for Piece-Wise Plane Detection and Reconstruction from a Single RGB Image
Authors: Yaxu Xie, Fangwen Shu, Jason Raphael Rambach, Alain Pagani, Didier Stricker
Summary: Piece-wise 3D planar reconstruction provides holistic scene understanding of man-made environments, especially for indoor scenarios. Different from other existing approaches, we start from enforcing cross-task consistency for our multi-task convolutional neural network, PlaneRecNet, which integrates a single-stage instance segmentation network for piece-wise planar segmentation and a depth decoder to reconstruct the scene from a single RGB image.
Preprint: https://www.dfki.de/web/forschung/projekte-publikationen/publikationen-filter/publikation/11908
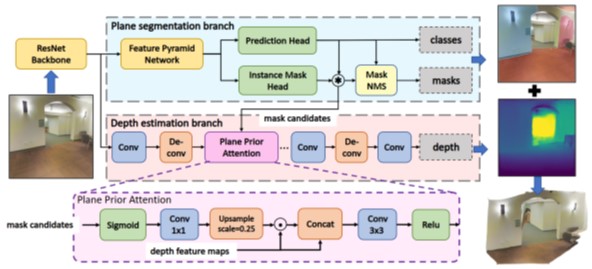
Contact: Alain Pagani

We are happy to announce that our paper “Multi-scale Iterative Residuals for Fast and Scalable Stereo Matching” has been accepted to the CSCS 2021!
The Computer Science in Cars Symposium (CSCS) is ACM’s flagship event in the field of Car IT. The goal is to bring together scientists, engineers, business representatives, and anyone who shares a passion for solving the myriad of complex problems in vehicle technology and their application to automation, driver and vehicle safety, and driving system safety.
In our work, we place stereo matching in a coarse-to-fine estimation framework to improve runtime and memory requirements while maintaining accuracy. This multiscale framework is tested for two state-of-the-art stereo networks and shows significant improvements in runtime, computational complexity, and memory requirements.
Link to preprint: https://arxiv.org/abs/2110.12769
Title: Multi-scale Iterative Residuals for Fast and Scalable Stereo Matching
Authors: Kumail Raza, René Schuster, Didier Stricker
KI zur Erkennung menschlicher Bewegungen und des Umfeldes
Adaptive Methoden die kontinuierlich dazu lernen (Lebenslanges Lernen), bilden eine zentrale Herausforderung zur Entwicklung von robusten, realitätsnahen KI-Anwendungen. Neben der reichen Historie auf dem Gebiet des allgemeinen kontinuierlichen Lernens („Continual Learning“) hat auch das Themenfeld von kontinuierlichem Lernen für Machinelles Sehen unter Realbedingungen jüngst an Interesse gewonnen.
Ziel des Projektes DECODE ist die Erforschung von kontinuierlich adaptierfähigen Modellen zur Rekonstruktion und dem Verständnis von menschlicher Bewegung und des Umfeldes in anwendungsbezogenen Umgebungen. Dazu sollen mobile, visuelle und inertiale Sensoren (Beschleunigungs- und Drehratensensoren) verwendet werden. Für diese verschiedenen Typen an Sensoren und Daten sollen unterschiedliche Ansätze aus dem Bereich des Continual Learnings erforscht und entwickelt werden um einen problemlosen Transfer von Laborbedingungen zu alltäglichen, realistischen Szenarien zu gewährleisten. Dabei konzentrieren sich die Arbeiten auf die Verbesserung in den Bereichen der semantischen Segmentierung von Bildern und Videos, der Schätzung von Kinematik und Pose des menschlichen Körpers sowie der Repräsentation von Bewegungen und deren Kontext. Das Feld potentieller Anwendungsgebiete für die in DECODE entwickelten Methoden ist weitreichend und umfasst eine detaillierte ergonomische Analyse von Mensch-Maschine Interaktionen zum Beispiel am Arbeitsplatz, in Fabriken, oder in Fahrzeugen.
Weitere Informationen: https://www.dfki.de/web/forschung/projekte-publikationen/projekte-uebersicht/projekt/decode
Contact: René Schuster
Mr. Habtegebrial is a PhD student at the Augmented Vision research department at the German Research Center for Artificial Intelligence (DFKI) and at the same named lab at the Technical University of Kaiserslautern (TUK). He was awarded the Google PhD Fellowship for his exceptional and innovative research in the field of “Machine Perception“. The PhD fellowship is endowed with 80,000 US dollars. Google also provides each of the PhD students with a research mentor.

Professor Didier Stricker, Tewodros’ PhD supervisor and head of the respective research areas at TUK and DFKI on the award for his PhD student: “I am very pleased that Tewodros received a PhD Fellowship from Google. He earned the honor through his outstanding achievements in his research work in Machine Perception and Image Synthesis.”
As part of his PhD studies Mr Habtegebrial has been working on Image-Based Rendering (IBR). Recently, he has worked on a technique that enables Neural Networks to render realistic novel views, given a single 2D semantic map of the scene. The approach has been published together with google and Nvidia at the pemium conference Neurips 2020. In collaboration with researchers at DFKI and Google research, he is working on spherical light-field interpolation and realistic modelling of reflective surfaces in IBR. This enables the implementation of new applications in the field of realistic virtual reality (VR) and telepresence. In addition to his PhD, topic he has co-authored several articles on Optical Character Recognition (OCR) for Amharic language, which is the official language of Ethiopia.
Further information:
https://research.google/outreach/phd-fellowship/recipients/
https://www.dfki.de/en/web/news/google-phd-fellowship
https://www.uni-kl.de/pr-marketing/news/news/tewodros-amberbir-habtegebrial-mit-google-phd-fellowship-ausgezeichnet
Hitachi and DFKI have been collaborating on various research projects for many years. Hitachi is now presenting joint current research with DFKI, the AG wearHEALTH at the Technical University of Kaiserslautern (TUK), Xenoma Inc. and sci-track GmbH, a joint spin-off of DFKI and TUK, in the field of occupational safety in a video.

{kind=link}
The partners have jointly developed wearable AI technology that supports the monitoring of workers’ physical workload, the capturing of workflows and can be used to optimize them in terms of efficiency, occupational safety and health. Sensors are loosely integrated into normal working clothes to measure the pose and movements of the body segments. A new approach to handle cloth induced artefakts allows full wearing comfort and high capturing accuracy and reliability.
Hitachi and DFKI will use the new solution to support worker and prevent dangerous poses to create a more efficient and safe working environment, while supporting full wearing comfort of any clothes.
Hitachi is a Principal Partner of the 2021 UN Climate Change Conference, known internationally as COP26, where it will present a video of its joint collaboration with DFKI, among other projects.
Further information:
Solution to visualize workers’ loads – Hitachi – YouTube
https://www.dfki.de/en/web/news/hitachi
Contact: Prof. Dr. Didier Stricker
Hitachi, Ltd. (TSE: 6501), headquartered in Tokyo, Japan, is contributed to a sustainable society with a higher quality of life by driving innovation through data and technology as the Social Innovation Business. Hitachi is focused on strengthening its contribution to the Environment, the Resilience of business and social infrastructure as well as comprehensive programs to enhance Security & Safety. Hitachi resolves the issues faced by customers and society across six domains: IT, Energy, Mobility, Industry, Smart Life and Automotive Systems through its proprietary Lumada solutions. The company’s consolidated revenues for fiscal year 2020 (ended March 31, 2021) totaled 8,729.1 billion yen ($78.6 billion), with 871 consolidated subsidiaries and approximately 350,000 employees worldwide. Hitachi is a Principal Partner of COP26, playing a leading role in the efforts to achieve a Net Zero society and become a climate change innovator. Hitachi strives to achieve carbon neutrality at all its business sites by fiscal year 2030 and across the company’s entire value chain by fiscal year 2050. For more information on Hitachi, please visit the company’s website at https://www.hitachi.com.