We are happy to announce that the Augmented Vision group will present 2 papers in the upcoming BMVC 2021 Conference, 22-25 November, 2021:
The British Machine Vision Conference (BMVC) is the British Machine Vision Association (BMVA) annual conference on machine vision, image processing, and pattern recognition. It is one of the major international conferences on computer vision and related areas held in the UK. With increasing popularity and quality, it has established itself as a prestigious event on the vision calendar. Homepage: https://www.bmvc2021.com/
The 2 accepted papers are:
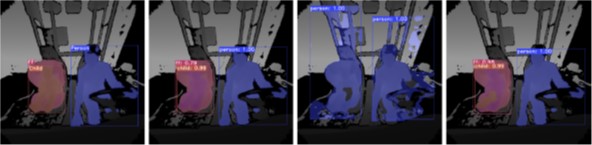
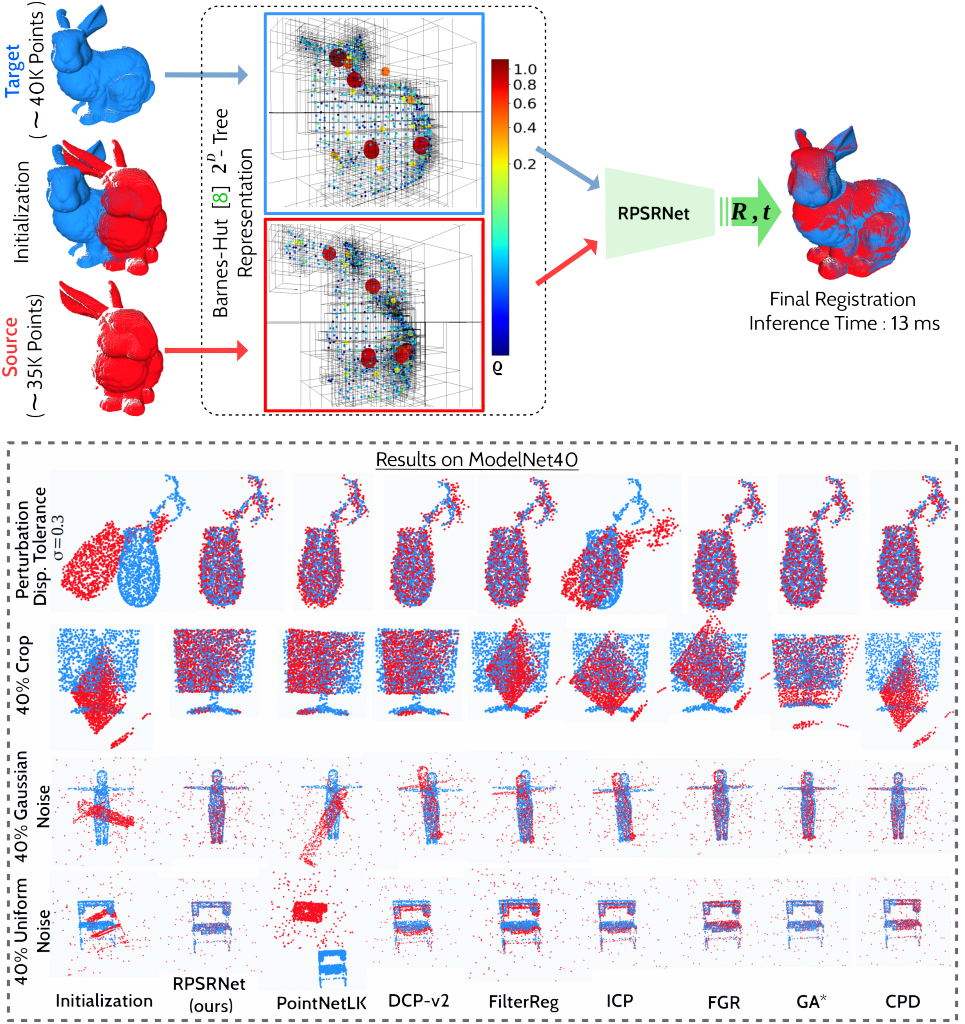
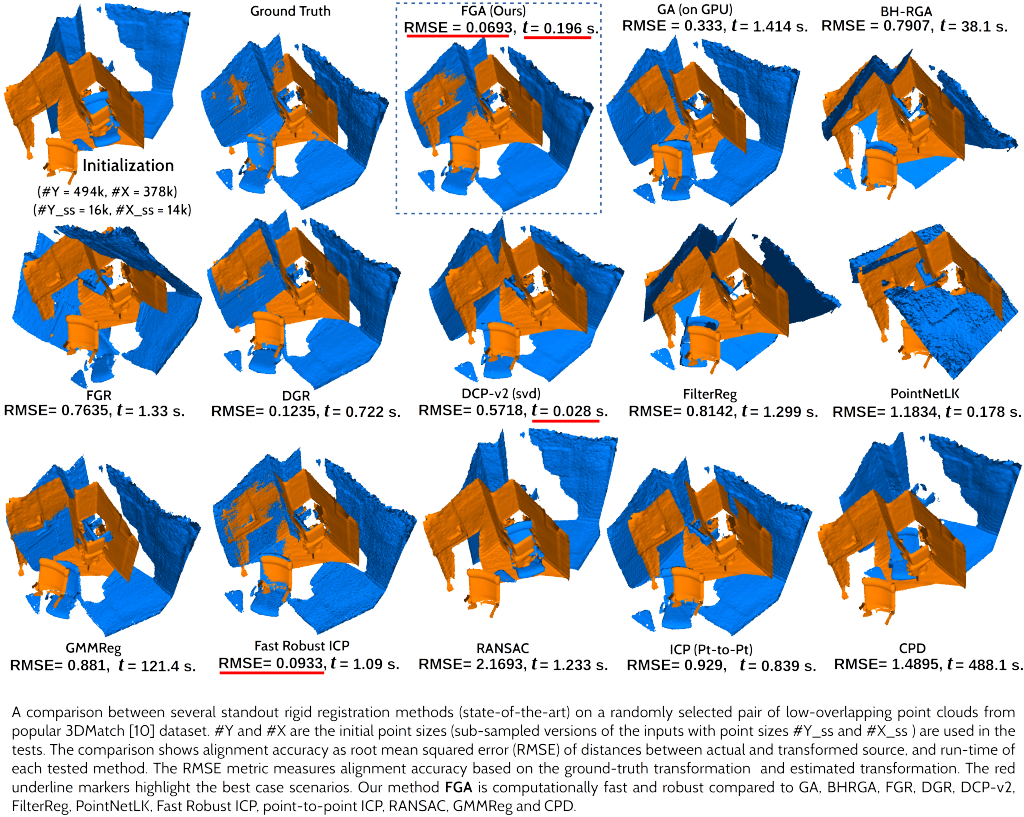
1. TICaM: A Time-of-flight In-car Cabin Monitoring Dataset
Authors: Jigyasa Singh Katrolia, Ahmed Elsherif, Hartmut Feld, Bruno Mirbach, Jason Raphael Rambach, Didier Stricker
Summary: TICaM is a Time-of-flight In-car Cabin Monitoring dataset for vehicle interior monitoring using a single wide-angle depth camera. The dataset goes beyond currently available in-car cabin datasets in terms of the ambit of labeled classes, recorded scenarios and annotations provided; all at the same time. The dataset is available here: https://vizta-tof.kl.dfki.de/
Video: https://www.youtube.com/watch?v=aqYUY2JzqHU
Contact: Jason Rambach
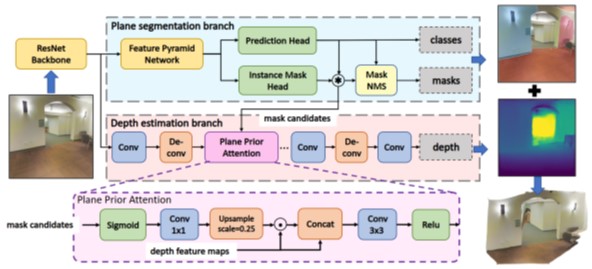
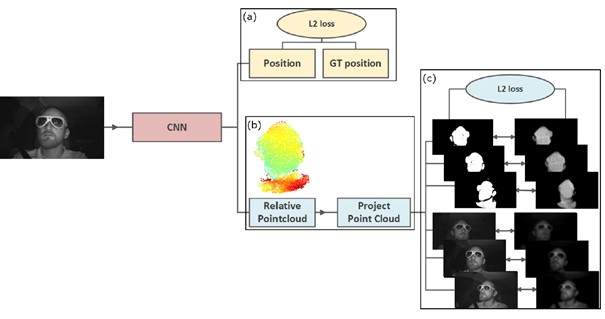
2. PlaneRecNet: Multi-Task Learning with Cross-Task Consistency for Piece-Wise Plane Detection and Reconstruction from a Single RGB Image
Authors: Yaxu Xie, Fangwen Shu, Jason Raphael Rambach, Alain Pagani, Didier Stricker
Summary: Piece-wise 3D planar reconstruction provides holistic scene understanding of man-made environments, especially for indoor scenarios. Different from other existing approaches, we start from enforcing cross-task consistency for our multi-task convolutional neural network, PlaneRecNet, which integrates a single-stage instance segmentation network for piece-wise planar segmentation and a depth decoder to reconstruct the scene from a single RGB image.
Preprint: https://www.dfki.de/web/forschung/projekte-publikationen/publikationen-filter/publikation/11908
Contact: Alain Pagani










{kind=link}