![]()
Evolving Personal to Organizational Knowledge Spaces
The objective of EPOS is to reduce the efforts for personal knowledge management and to evolve personal to organizational knowledge spaces. EPOS addresses the following topics:
- workspace modelling, techniques for user observation and context identification
- identification of information needs, query modification for collaborative information retrieval
- communication structures in interacting knowledge workspaces
- leveraging individual native information structures to models and ontologies, evidence calculation for ontology creation
- communication and negotiation protocols on the meta-level
- ontology-based visualization components, configuration rules for task-specific information-visualization.
EPOS Motivation
Knowledge workers put a lot of effort during every day’s work in structuring their own information. This is done with the help of email tools, file directories, or bookmarks and the way this is done depends highly on the individual manner of working. Contrary to that are the knowledge management goals of a company: global collection, structuring and distribution of knowledge. Thus, there is a discrepancy between the global benefit for the organization and the personal benefit for the individual knowledge worker.
While the organization asks for universally applicable and standardized persistent structures, processes, and work organizations to achieve and maintain universally accessible information archives, the individual knowledge worker requests individualized structures and flexibility in processes and work organization in order to reach optimal support for the individual activities.
Therefore, EPOS investigates a bottom-up evolutionary approach to resolve this discrepancy. The individual knowledge workspace, realized as a set of agents in the knowledge workers’ personal computer, will provide adequate and task-specific supporting information to the human. In parallel, the system will observe the work and the users’ ways of information access/ handling and automatically learn about intentions, structures, ontologies, and work processes. Towards the user, the knowledge workspace thus acts as an adaptive information assistant. In order to present this information that has been gathered behind the scenes advanced Information Visualization techniques are necessary.
The individual face of the knowledge workspace is complemented by globally oriented sharing and exchange facilities. Interacting agents from different workspaces synchronize information needs, balance structures, ontologies, and process models, and exchange context-specific relevant information. A society of agents, represented by the collection of individual knowledge workspaces, will thus reach a common and shared understanding of the structured information and knowledge used in their realm, and finally, contribute to the organizational memory.
EPOS Vision (slides in english, pdf) (Kurzversion in deutsch, pdf)
EPOS and gnowsis in the DFKI Newsletter
- in 15/2005 (page 10: English , German/deutsch)
- in 17/2006 (page 5: English , German/deutsch)
EPOS succeeds the FRODO (Framework for Distributed Organization Memories) project. In FRODO several assumptions, methods, and techniques have already been tackled.
The works towards the Semantic Desktop lead to the EU IP-Project Nepomuk
Successor projects
EPOS finished in 2005, but research as continued in these projects:
- EU Integrated Project Nepomuk
- MyMory
- ADIB – Adaptive Information Delivery
- lots of components are published as open source at OpenDFKI
- a DFKI spin-off the gnowsis.com
- We were part of the EU IP ForgetIT contributing with our new Semantic Desktop to Managed Forgetting, Contextualized Remembering and Synergetic Preservation (Find videos and more detailed explanations of our newest Semantic Desktop at the Personal Preservation Pilot webpage)
- supSpaces the Semantic Desktop Server is the back-end of supSpaces
- (2019) Our work culminated in our DFKI CoMem at comem.ai
In the following we present more details of the EPOS project.
EPOS Research lines
Personal Information Models & Ontologies
Short description of the destination of this part of the EPOS project:
- With e-mail and file folders, bookmark hierarchies etc., knowledge workers already use and continuously maintain a lot of structures that reflect parts their knowledge (e.g., about people and projects), their domain of interest, or world view.
- These structures can be seen as valuable input for organizational knowledge management, but also as a means to personalize information delivery to the user (e.g., by mapping search results onto the specific user’s structure).
- However, the flexibility that the current mode of interaction with these structures offers, entails also serious drawbacks for the exploitation for automated information services: Parts of the structures are redundant or contradictory, the elements don’t have a clear semantics, etc.
- Goal of this project line is to integrate the various native structures of one knowledge workspace into one Personal Information Model (PIM) that on the one hand reflects the personal structures, but on the other hand has a clear formal semantics. These PIM can than be used for knowledge exchange between workspaces and for communication with an Organizational Memory.
Research Topics:
- Specify the Personal Information Model
- Analysis of exploitable “native structures” and their intended semantics
- Definition of a representation framework that is sufficient to reflect native structures
- Techniques for leveraging native structures to the PIM
- Implementation of the PIM and a communication interface to query and manipulate it
- Framework for Inter-PIM communication
- Mappings between several Personal Information Models
- Re-use of fragments from external models
- Integration of Personal Information Models with (organizational) ontologies
The work started in the EPOS project resulted and influenced the work done in the Nepomuk project and there the PIMO (Personal Information Model Ontology) and finally also our work in CoMem and SensAI
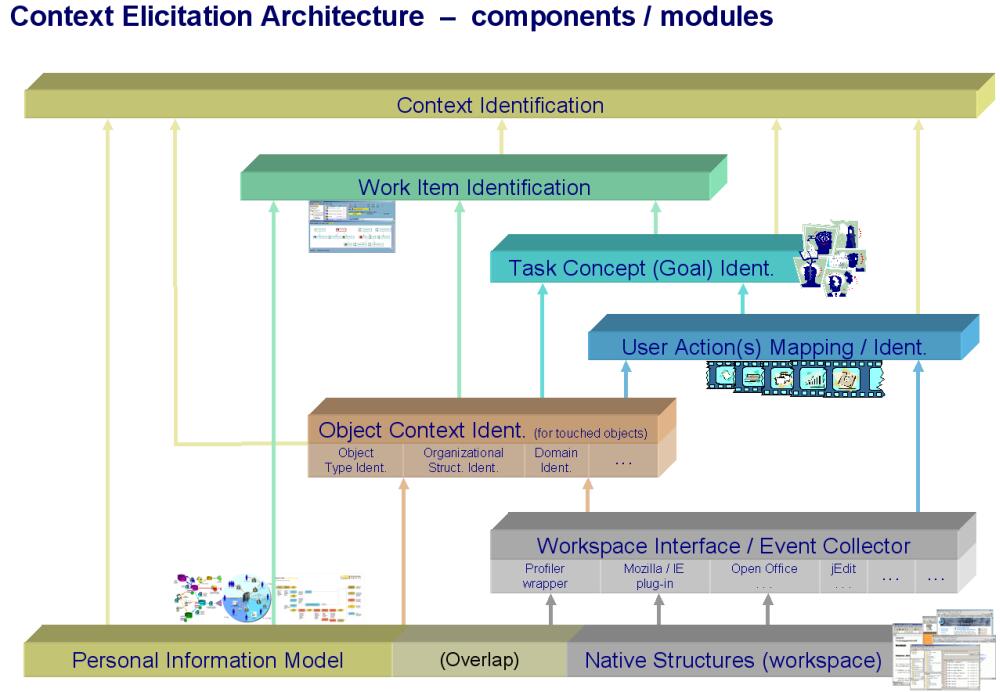
Context Elicitation by User Observation in EPOS
The goal is to estimate a user’s context automatically and, hence, without disturbing and distracting him. When we talk about context we are focusing on contextual information relevant for (personal) knowledge management aspects. This means, we are not sensoring the room temperature or the user’s heart beat frequency.
We are mainly observing the user’s interactions with his PC. (Personal) Knowledge Management work is focussing on text work. Therefore, we are observing text-oriented actions in particular. For example, writing or replying to emails, or browsing the web, etc.
The user observation is done by a plugins an the user observation framework. The observed user actions are taken as evidences.
Short description of the destination of this part of the EPOS project:
- Human uses the computer to help him do his work.
- Usage of computer is done in a nowadays typical way, i.e., a graphical user interface providing access to applications running on the user’s machine.
- Applications, tools, operating system components, etc. allow for interactions with objects on the machine and in the world (documents, e-mails, etc.).
- Such objects can be created, stored, viewed, edited, etc.
- We observe the user doing his work in order to get a clue about his intentions and goals.
- The user’s intentions, goals, application usage are part of the context he is in.
- This context will be used to support the human’s work with context-sensitive, pro-active knowledge assistance which will make his work easier. Think of an intelligent assistant helping you with
- minor working steps
- remembering you of important appointments
- showing you related information
- example of our assistant bar (screenshot )
Research Topics:
- Specify a generic Workspace Model (objects, operations / operators on these objects)
- Instantiate and observe the / all / some applications and operating systems components (web browser, e-mail client, Open Office, text editor, file explorer, notes application, proFiler/brainfiler (multi-criterial document archive and classification))
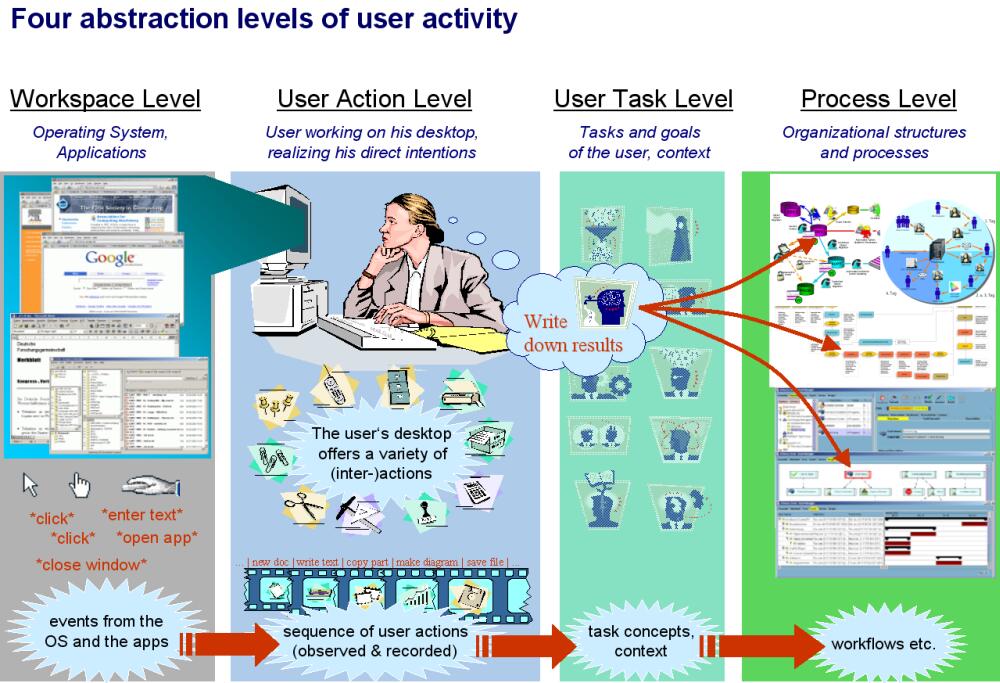
- Specify different levels of user activity (4 levels of user activity (image))
- Mapping observed workspace events to user actions (user intentions, i.e., short-term goals) -> plan recognition
- Mapping user actions to task concepts (user goals, i.e., mid-term goals): goal elicitation, task concept ontology (hierarchical task ontology)
- Mapping task concepts to workflow working steps (user is embedded in / assigned to workflows -> long-term goals); process / task identification; semantic description of workflows / tasks
- Create a context elicitation framework (context elicitation architecture (image))
The results are part of Sven Schwarz’ PhD “Schwarz S (2010), “Context-Awareness and Context-Sensitive Interfaces for Knowledge Work, 2010. Disertation, Kaiserslautern University, Verlag Dr. Hut.
{kind=link}
{kind=link}
{kind=link}
InfoVis
The information available within one user’s personal knowledge space consists of highly complex structures. These may be personal information models underlying the identified processes the user is performing or simply large amounts of pieces of information as a result of previously expressed information needs. This complexity even increases when we consider the set of the users’ personal knowledge spaces that together form the organizational memory. Intelligent visualization techniques help the users to cope with that complexity.
When we have a closer look at these knowledge spaces, we identify four domains:
- the document spaces,
- the personal and organizational information models,
- the processes,
- the users.
Each domain is usually populated by a set of entities that are implicitly or explicitly linked to other entities within the same or within other domains: Each of the users within the organization has got one or more document spaces to store his information items. For structuring his knowledge he relies on his personal information model. Additionally, on the level of the organizational memory, there is one global model, the organization’s ontology. Besides that many process models describe different tasks of the user’s daily work.
In this domain model we find three dimensions to consider for visualization:
- each single entity in a domain (which can be a multivariate space itself),
- a set of entities in one domain (e.g., all processes a user is involved in),
- the inter-domain views (e.g., the connection of process steps with knowledge from the organizational memory).
While there exist many research results that address problems from the first and second dimension, there is still a demand for research in dimension three. Especially, here we get domain-spanning information of very different kinds: This may on one hand be arbitrary structural information linking objects from two or more domains or on the other hand be a large set of query results from one domain.
During the EPOS project we want to address both of these problem-classes by generalizing existing techniques within the Information Visualization domain and automatically selecting the appropriate metaphors from a given set and applying them to the given problem.
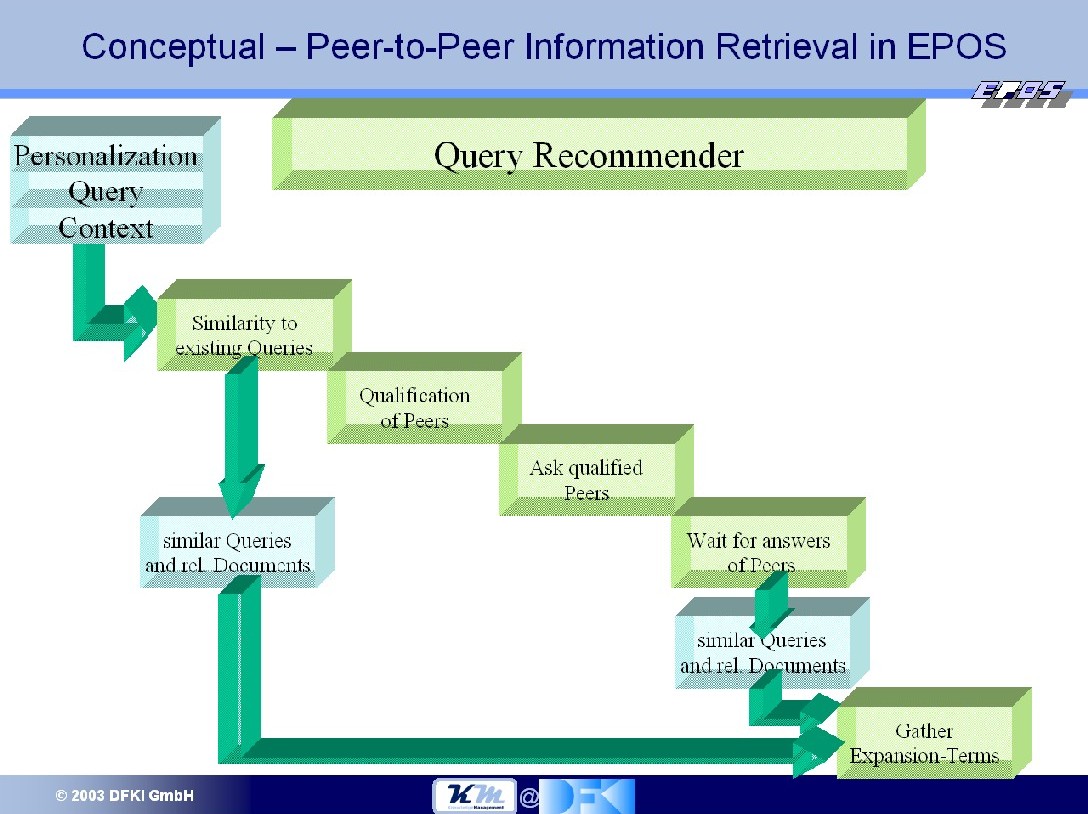
Peer-to-Peer Information Retrieval
Precise satisfaction of information needs in interacting knowledge workspaces
- Improve user satisfaction by collaborative information retrieval
- exploit query experience resulting from previous queries together with user feedback on the query results
- associate query experience with the appropriate context and model elements
- re-use query experience to improve new user queries in a way that the results will better fit to the current context and the assumed user intentions
- Tap personal knowledge workspaces as an organizational memory resource
- communicate information needs across workspaces
- integrate answers from different workspaces to satisfy the query
Reuse query experience in order to improve search in collaborative workspaces
- Relevance feedback allows to save positive examples of query results as reusable experience
- Learn about successful query-result-concepts based on term occurrence
- Retrieved information objects are associated with the personal information models and the retrieval context. This association is transferred to the corresponding query experiences
- Current information needs are better satisfied by using stored query experiences for query reformulation
- The exchange of stored query experiences between individual workspaces helps to identify and build thematic communities
- other users in similar situations profit from previous experience
- particular queries are routed to appropriate partner workspaces to retrieve information across workspace boundaries
Research Topics:
- Peer-To-Peer IR (P2P-IR)
- How to identify the peers to inform/query ?
- How to merge search results from several peers?
- Quality estimation
- How relevant are the results from other peers?
- What makes a peer a specialist/expert/layman/amateur?
- Conceptional Level Query Manager, Query Recommender
- Detail Level (detailed information is presented here and here and here )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Projects and Groups
Specter
Our partner DFKI-project Specter dealing with context- and affect-aware personal assistance in instrumented environments, DFKI Saarbrücken
EDAMOK
Enabling distributed and autonomous management of knowledge; ITC irst in Trento, Italy
SWAP
EU-project in the IST-programme considered with using Semantic Web and P2P technologies for knowledge management. Bibster is a system that builds on SWAP technology and assists researchers in managing, searching, and sharing bibliographic data in a peer-to-peer network.
AWAKE
Knowledge Sharing in Heterogeneous Expert Communities. The goal is to develop an experimental, agent-based platform, making it possible to explore and to compare different methods for knowledge sharing and information search in heterogeneous expert communities. Awake focuses on capturing and visualizing implicit knowledge. Michael Wurst visited the EPOS team.
Gnowsis
The goal is to develop a semantic desktop based on Semantic Web technology. Leo Sauermann joined our project team in July 04. – and after some years now made a spin-off gnowsis.com in 2009
Haystack
Haystack also focuses on the individual information handling perspective with Semantic Web technology.
NEPOMUK
NEPOMUK brings together researchers, industrial software developers, and representative industrial users, to develop a comprehensive solution for extending the personal desktop into a collaboration environment which supports both the personal information management and the sharing and exchange across social and organizational relations. The work done in EPOS heavily influenced the project, e.g., the PIMO
Members of the EPOS project
(here’s a team picture from a long time ago)
{kind=link}
- Heiko Maus (project lead)
- Ludger van Elst
- Sven Schwarz
- Leo Sauermann
- Jan-Thies Heinrich (formerly Bähr)
- Andreas Lauer
Associated Researchers
- Ansgar Bernardi
- Peter Dannenmann
- Rolf-Hendrik van Lengen
- Michael Sintek
- Malte Kiesel
- Barbara Spillmann (then Uni Bern)
- Armin Hust
Students
(long long time ago…thanks to you all!)
- Björn Endres
- Stefan Weisenberger
- Malte Kiesel (then staff 🙂
- Markus Reinhardt
- Robinson Aschoff, University of Heidelberg
- Frank Osterfeld
- Panitini Madhu Satyanarayana
- Pascal Arweiler, FH Birkenfeld
- Michael Breidel, FH Birkenfeld
- Emmanuel Gasne, ENST Bretagne, France
- Björn Endres
- Jordi Hernandez
- Nagaseshagiri Poola
- Christian Schütz
Tools
Tools of the EPOS project. (notice: not all tools are available anymore):
RDF tools
see FRODO Tools section or RDF2Java
FRODO TaskMan
Workflow management assistant tool for weakly structured processes with the concept of weakly structured workflows or agile knowledge workflows (our new term for this).
Semantic Desktop gnowsis
gnowsis is a personal semantic web desktop server – Semantic Desktop for short. Like a local webserver, that can be seen only by you and that contains your own files, emails, friends and photos. This semantic desktop will interact with the Personal Information Model (PIM)
Nepomuk Semantic Desktop
The follow-up of the gnowsis Semantic Desktop
User Context Framework
Hosts the platform for researchers and practitioners about user context. In our view, user context is the things that influence knowledge work. Through user observation a context-sensitive application can detect the user’s current work context and support the user with suggestions and other services…
Mozilla Plugins for UserObservation
The enhanced Mozilla extensions are available as DragonTalk, an open-source project.
Nabu
Nabu is a plugin for Jive Messenger, a server implementation of the Jabber Instant Messaging protocol. It provides server-side logging of chat conversations and related events. The logged data is stored in a semantic graph, using the RDF W3C standard.
Jatke
JATKE is a Protégé plug-in that provides a unified platform for ontology learning. It is capable of employing and combining arbitrary modules, and thus provides a custom setup for every scenario. JATKE features three different module abstraction levels (Information/Source, Evidence, Proposal), hence facilitating easy reuse and combination of existing modules.
Dragontalk
The Dragontalk project provides a set of extensions for the Mozilla products Thunderbird (email client) and Firefox (web browser). One of the goals of the project is to get information about the user’s operations. For instance, if the user sends or replies to an email, Dragontalk sends a SendEmail or a ReplyToEmail event to some port where an XMLRPC listener can catch it. This is used to elicit the user’s context automatically.
rdfhomepage
RDFHomepage creates personal homepages based on your RDF data. Never more duplicate the information in your bibtex, FOAF file, etc. by manually coding ugly and complicated HTML by hand! Let rdfhomepage create it for you! (last one ctive is the one of Heiko Maus
Aperture
grew out of the Gnowsis Semantic Desktop initiative: Aperture is a Java framework for extracting and querying full-text content and metadata from various information systems (e.g. file systems, web sites, mail boxes) and the file formats (e.g. documents, images) occurring in these systems. (also used in the Nepomuk project)
OpenDFKI.de
Visit also our department’s Open Source platform for more tools such as a Semantic Wiki
Contact
Dr. Heiko Maus